논문 링크: Averaging Weights Leads to Wider Optima and Better Generalization
논문 정보
| 항목 | 내용 |
|---|---|
| Venue | Conference on Uncertainty in Artificial Intelligence (UAI) |
| 출판 시점 | 2018년 |
| 저자 | Pavel Izmailov, Dmitrii Podoprikhin, Timur Garipov, Dmitry Vetrov, Andrew Gordon Wilson |
| 소속 | Cornell University, Higher School of Economics, Samsung-HSE Laboratory, Samsung AI Center in Moscow, Lomonosov Moscow State University |
핵심 아이디어
SWA(Stochastic Weight Averaging) 는 SGD 학습 과정에서 나온 여러 weight를 평균내어 하나의 모델을 만드는 방법이다.
일반적인 SGD는 learning rate를 줄여가며 하나의 수렴점으로 이동한다.
반면 SWA는 일정하거나 주기적인 learning rate로 좋은 성능을 내는 영역 주변을 계속 탐색하고, 그 과정에서 얻은 weight들을 평균낸다.
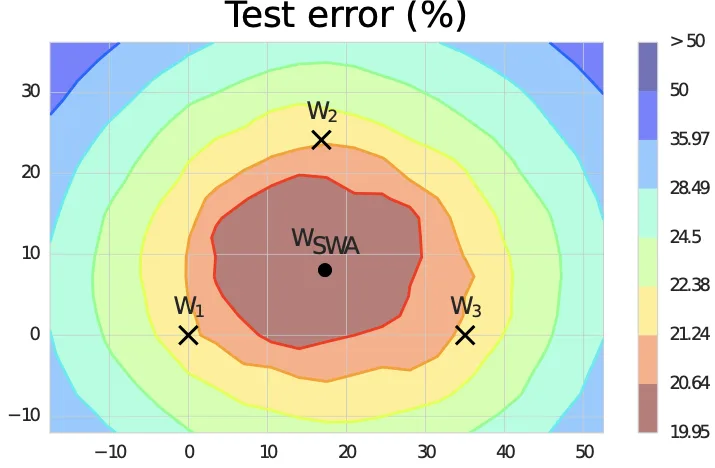
논문 Figure 1 일부. FGE가 sampling한 weight 의 평균이 이고, 이 평균점이 더 낮은 test error region 중심부에 위치한다.
핵심은 prediction을 평균내는 ensemble이 아니라, weight 자체를 평균낸다는 점이다.
여기서 는 SGD trajectory 중 선택된 모델 weight이다. 최종적으로는 하나만 사용하므로 test-time cost는 일반 single model과 같다.
교수님 관점에서 이 논문을 한 문장으로 요약하면 다음과 같다.
SGD가 loss가 낮은 영역의 주변부를 돌아다닌다면, 그 weight들의 산술평균은 더 중심부의 flat한 해를 줄 수 있다.
문제 설정
학습 데이터에 대한 empirical risk를 다음과 같이 두자.
일반적인 SGD update는 다음과 같다.
여기서 는 mini-batch이고, 는 learning rate이다. 기존 학습에서는 를 점점 줄여서 하나의 수렴점 로 이동한다.
SWA는 수렴 이후에도 큰 learning rate를 유지하거나 cyclical schedule을 사용하여 여러 해를 sampling한다.
그리고 이들의 평균을 최종 해로 사용한다.
이때 중요한 것은 들이 완전히 다른 basin에 있는 것이 아니라, 비슷하게 좋은 성능을 내는 같은 low-loss region 안에 있다는 점이다.
왜 weight averaging이 도움이 되는가
논문은 SGD가 좋은 성능을 내는 영역의 중심이 아니라, 그 주변부에 머무르는 경향이 있다고 설명한다.
특히 decaying learning rate로 학습하면 SGD는 loss가 낮은 영역의 한 지점에 수렴하지만, 그 지점이 test error 관점에서 가장 안정적인 중심점은 아닐 수 있다.
SWA는 여러 SGD proposal을 평균내면서 더 넓고 평평한 영역의 중심으로 이동한다. 이런 flat minimum은 작은 weight perturbation에도 loss가 크게 증가하지 않기 때문에 더 좋은 일반화 성능을 기대할 수 있다.
직관적으로 보면 다음과 같다.
| 방법 | 위치 | 특징 |
|---|---|---|
| SGD | low-loss region의 주변부 | train loss는 낮지만 sharp한 방향이 존재할 수 있다. |
| SWA | low-loss region의 중심부 | train loss는 조금 높을 수 있지만 test error가 더 낮아질 수 있다. |
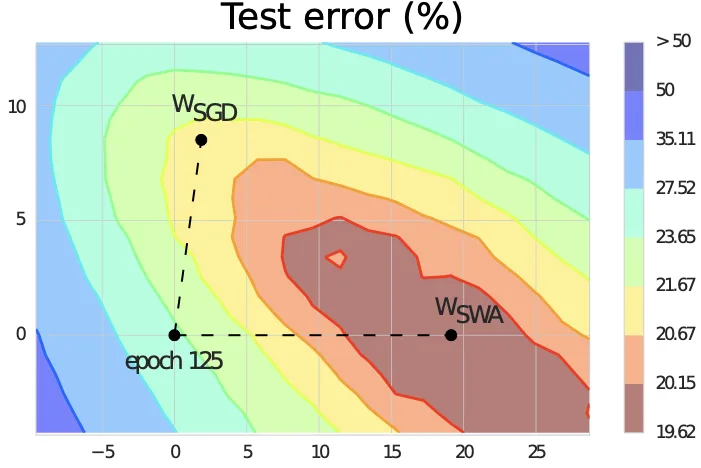
논문 Figure 1 일부. 는 낮은 train loss 주변부에 있고, 는 test error가 더 낮은 넓은 영역으로 이동한다.
이를 Taylor expansion으로 생각해보자. 어떤 해 주변에서 작은 perturbation 를 주면 loss는 다음처럼 근사된다.
local minimum 근처에서는 이므로 곡률을 결정하는 항은 Hessian 이다.
만약 의 큰 eigenvalue가 많다면, 어떤 방향으로 조금만 움직여도 loss가 크게 증가한다. 이런 해를 sharp minimum이라고 볼 수 있다. 반대로 SWA가 찾는 해는 여러 방향에서 loss 증가가 완만한 flat minimum에 가깝다.
Learning Rate Schedule
SWA는 SGD가 다양한 weight를 탐색하도록 learning rate를 너무 빨리 줄이지 않는다. 논문에서는 두 가지 방식을 사용한다.
Constant learning rateCyclical learning rate
Cyclical learning rate는 일정 주기마다 큰 learning rate로 다시 올라가게 하여 weight space를 더 넓게 탐색한다.
다만 FGE(Fast Geometric Ensembling) 와 달리, SWA는 각 모델의 prediction을 ensemble하지 않고 weight를 평균낸다.
논문에서 사용하는 cyclical schedule은 한 cycle 안에서 learning rate가 큰 값 에서 작은 값 로 감소한다. 단순화하면 다음과 같이 볼 수 있다.
여기서 는 cycle length이다. cycle의 끝, 즉 learning rate가 낮아진 시점의 weight를 평균에 포함한다.
constant learning rate를 쓰는 경우에는 더 간단하게
로 두고 매 epoch마다 weight를 평균에 포함할 수 있다.
SWA 알고리즘
전체 흐름은 단순하다.
- 일반 SGD로 어느 정도 학습된 모델을 준비한다.
- constant 또는 cyclical learning rate로 추가 학습한다.
- 일정 주기마다 weight를 저장한다.
- 저장한 weight들의 running average를 갱신한다.
- 마지막에
BatchNormstatistic을 다시 계산한다.
running average는 다음과 같이 업데이트할 수 있다.
여기서 은 지금까지 평균에 포함된 모델 수이고, 는 새로 추가할 weight이다.
이를 반복식으로 쓰면 다음과 같다.
즉 모든 weight를 저장하지 않아도 running average만 유지하면 된다. 추가 메모리는 평균 weight 하나만큼만 필요하다.
Batch Normalization 처리
SWA에서 주의할 점은 BatchNorm이다.
weight를 평균낸다고 해서 BatchNorm의 running mean, running variance도 자동으로 올바르게 평균되는 것은 아니다.
따라서 SWA weight를 얻은 뒤 학습 데이터를 한 번 forward pass하여 BatchNorm statistic을 다시 계산한다.
PyTorch에서는 보통 모델을 train mode로 둔 상태에서 gradient 없이 데이터를 한 번 통과시키는 방식으로 처리할 수 있다.
FGE와의 관계
FGE는 여러 모델의 output을 평균내는 ensemble 방식이다. SWA는 FGE와 비슷한 trajectory에서 모델들을 얻지만, output 대신 weight를 평균낸다.
차이는 다음과 같다.
| 방법 | 평균 대상 | Test-time 비용 |
|---|---|---|
| FGE | prediction | 모델 개수만큼 증가 |
| SWA | weight | single model과 동일 |
논문은 weight들이 충분히 가까운 영역에 있다면, weight averaging으로 얻은 모델의 prediction이 ensemble prediction을 근사할 수 있다고 설명한다.
수식으로 보면 다음과 같다. 모델 prediction을 라 하고, 각 FGE proposal을
라고 두자. 평균 정의에 의해
이다. 이제 를 에서 1차 Taylor expansion하면
ensemble prediction은
이고 가운데 1차항은 0이 된다. 따라서
즉 weight들이 충분히 가까우면, weight average 모델 하나가 ensemble prediction을 2차 오차 수준으로 근사할 수 있다.
실험 결과
논문은 CIFAR-10, CIFAR-100, ImageNet에서 SWA를 기존 SGD와 비교한다.
VGG, ResNet, WideResNet, DenseNet, PyramidNet, Shake-Shake 등 다양한 architecture에서 성능 향상이 확인된다.
대표적인 결과는 다음과 같다.
| Dataset | 관찰 |
|---|---|
| CIFAR-10 | ResNet, WideResNet 등에서 SGD보다 높은 accuracy를 보인다. |
| CIFAR-100 | SWA가 SGD보다 일관되게 좋은 test accuracy를 보인다. |
| ImageNet | ResNet, DenseNet 계열에서도 추가 학습만으로 성능 개선을 보인다. |
중요한 점은 SWA가 큰 구조 변경을 요구하지 않는다는 것이다.
기존 SGD 학습 pipeline 뒤에 weight averaging과 BatchNorm statistic update를 추가하면 된다.
장점
- 구현이 단순하다.
- 추가 메모리 비용이 작다.
- 최종 모델은 하나이므로 inference 비용이 증가하지 않는다.
- 다양한 architecture에 적용할 수 있다.
- flat minimum을 찾아 일반화 성능을 개선할 수 있다.
한계
SWA는 weight averaging이 의미 있으려면 학습 trajectory가 좋은 성능을 내는 영역을 탐색해야 한다. 너무 이른 시점부터 평균을 내거나, learning rate schedule이 적절하지 않으면 성능 향상이 제한될 수 있다.
또한 BatchNorm statistic을 다시 계산해야 하므로 이 단계를 빠뜨리면 성능이 제대로 나오지 않을 수 있다.
정리
SWA는 “SGD가 찾은 하나의 점”보다 “SGD가 지나간 좋은 점들의 평균”이 더 일반화가 잘 될 수 있다는 관찰에서 출발한다. 결과적으로 SWA는 sharp한 주변부가 아니라 넓은 flat region의 중심에 가까운 해를 찾는다.
이 논문의 의의는 flat minimum과 generalization의 관계를 실험적으로 강하게 보여주면서, 동시에 매우 간단한 학습 기법을 제안했다는 점이다. 기존 모델 구조나 loss를 바꾸지 않고도 적용할 수 있기 때문에 실용적인 optimization trick으로 볼 수 있다.