논문 링크: Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
논문 정보
| 항목 | 내용 |
|---|---|
| Venue | Conference on Neural Information Processing Systems (NeurIPS) |
| 출판 시점 | 2020년 |
| 저자 | Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Kuttler, Mike Lewis, Wen-tau Yih, Tim Rocktaschel, Sebastian Riedel, Douwe Kiela |
| 소속 | Facebook AI Research, University College London, New York University |
핵심 아이디어
RAG(Retrieval-Augmented Generation) 는 pretrained seq2seq model이 가진 parametric memory와 외부 문서 index가 가진 non-parametric memory를 결합하는 방법이다.
기존 language model은 factual knowledge를 parameter 안에 저장한다. 하지만 knowledge-intensive task에서는 다음 문제가 생긴다.
| 문제 | 의미 |
|---|---|
| 접근성 | 모델이 어떤 근거로 답했는지 알기 어렵다. |
| 업데이트 | parameter에 저장된 지식은 쉽게 교체하기 어렵다. |
| 정확성 | 자주 등장하지 않는 사실이나 최신 사실에서 hallucination이 생길 수 있다. |
| 출처 | 답변의 provenance를 제공하기 어렵다. |
RAG의 핵심은 간단하다.
Generator가 바로 답을 생성하지 않고, 먼저 관련 문서 를 검색한 뒤 그 문서를 조건으로 답변 를 생성한다.
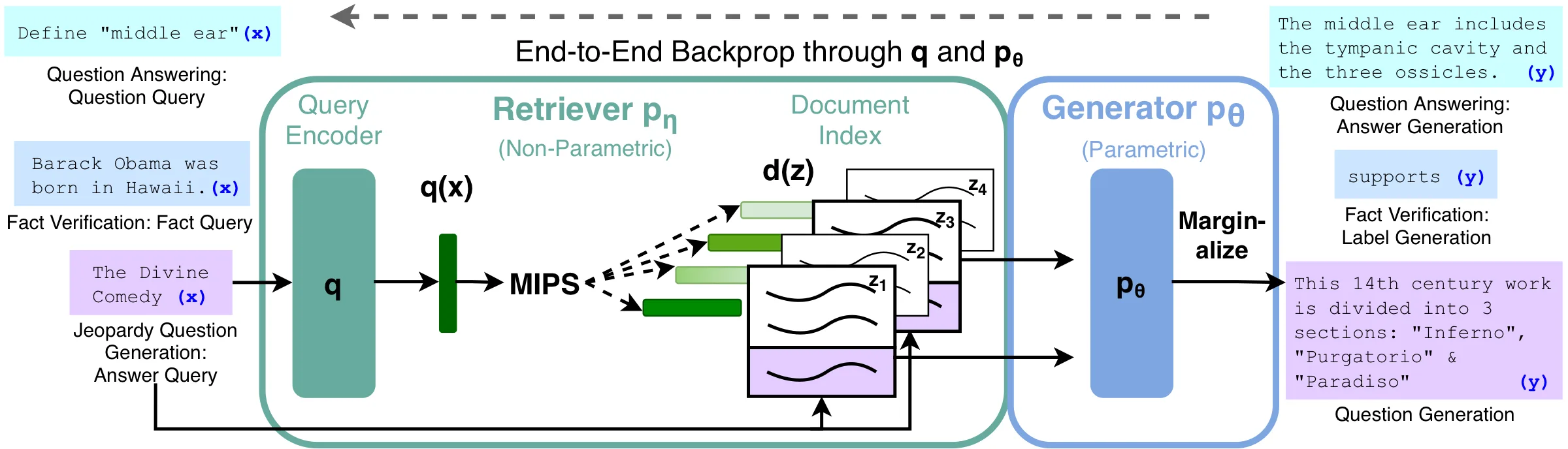
논문 Figure 1. Query encoder와 document index가 top- 문서를 검색하고, generator는 각 문서를 조건으로 sequence를 생성한다. 최종 확률은 문서 latent variable 에 대해 marginalization한다.
이 구조는 closed-book generation과 open-book retrieval의 중간에 있다. 모델 내부 지식만 믿지 않고, 외부 Wikipedia index를 검색해서 generation에 사용한다.
문제 설정
입력 query를 , 생성해야 할 target sequence를 라 하자. RAG는 문서 를 직접 관측된 입력으로 보지 않고 latent variable로 둔다.
구성 요소는 두 가지다.
| 구성 요소 | 확률 모델 | 역할 |
|---|---|---|
| Retriever | query 에 대해 관련 문서 를 찾는다. | |
| Generator | 검색 문서 를 조건으로 token을 생성한다. |
여기서 는 retriever parameter이고, 는 generator parameter이다.
논문 구현에서 retriever는 DPR(Dense Passage Retrieval) 기반 bi-encoder이고, generator는 BART-large이다. 문서 index는 2018년 12월 Wikipedia dump를 100-word chunk로 나누어 만든 약 2,100만 개 문서로 구성된다.
Retriever
DPR은 query encoder와 document encoder를 따로 둔다. 문서 의 embedding을 , query 의 embedding을 라 하면 retrieval score는 inner product로 계산된다.
즉 query와 document embedding이 가까울수록 높은 retrieval probability를 갖는다. Top- 문서를 찾는 문제는 다음과 같은 MIPS(Maximum Inner Product Search) 문제다.
논문은 이를 FAISS와 HNSW approximation으로 빠르게 수행한다. 중요한 구현 선택은 document encoder와 document index를 고정한다는 점이다. 학습 중에는 query encoder와 BART generator를 fine-tuning하지만, 전체 Wikipedia index를 계속 다시 만드는 비용은 피한다.
RAG-Sequence
첫 번째 모델은 RAG-Sequence이다. 하나의 target sequence 전체가 같은 문서 를 조건으로 생성된다고 가정한다.
Autoregressive generator로 풀어 쓰면 다음과 같다.
교수님 관점에서 보면, 이 식은 문서 posterior를 sequence 단위로 mixture하는 모델이다. 각 문서가 하나의 explanation candidate가 되고, 최종 sequence likelihood는 문서별 likelihood의 weighted sum이 된다.
RAG-Token
두 번째 모델은 RAG-Token이다. RAG-Sequence와 달리 token마다 다른 문서가 쓰일 수 있다고 본다.
RAG-Sequence는 먼저 문서를 고르고 그 문서로 전체 답변을 만든다. 반면 RAG-Token은 각 token 위치에서 문서별 token probability를 marginalize한다.
| 모델 | 문서 선택 단위 | 장점 | 단점 |
|---|---|---|---|
| RAG-Sequence | sequence 전체 | 하나의 문서 근거가 유지되어 해석하기 쉽다. | 여러 문서의 정보를 섞기 어렵다. |
| RAG-Token | token 단위 | 답변 중간에 다른 문서 정보를 조합할 수 있다. | 문서 posterior가 token마다 바뀌어 해석이 복잡하다. |
RAG-Sequence는 document-level mixture이고, RAG-Token은 token-level mixture이다.
학습 Objective
학습 데이터가 로 주어졌다고 하자. RAG는 정답 문서 supervision 없이 target sequence의 negative log-likelihood를 최소화한다.
여기서 는 RAG-Sequence 또는 RAG-Token의 marginal likelihood이다. 문서 는 label로 주어지지 않지만, likelihood를 높이는 방향으로 query encoder가 어떤 문서를 가져와야 하는지 학습된다.
이 점이 중요하다. RAG는 retrieve-and-read pipeline처럼 gold passage를 명시적으로 맞추는 것이 아니라, generation loss를 통해 retriever를 간접적으로 학습한다.
다만 document encoder는 고정한다. 문서 embedding까지 업데이트하면 index 전체를 재계산해야 하므로 비용이 커진다. 따라서 논문은 다음 parameter만 fine-tuning한다.
| Parameter | 학습 여부 |
|---|---|
| BART generator | 학습한다. |
| DPR query encoder | 학습한다. |
| DPR document encoder | 고정한다. |
| Wikipedia document index | 고정한다. |
Decoding
RAG-Token은 token 단위 marginal probability가 있으므로 일반적인 beam search에 비교적 자연스럽게 넣을 수 있다.
반면 RAG-Sequence는 sequence 전체 likelihood가 문서별 sequence likelihood의 합이다. 일반적인 autoregressive factorization처럼 바로 beam search를 적용하기 어렵다.
논문은 RAG-Sequence에 대해 각 문서마다 beam search를 수행한 뒤, 후보 sequence들을 모아 다시 marginal score를 계산한다. 이 방식은 정확하지만 비싸다. 그래서 후보 set에 없는 sequence probability를 0으로 근사하는 Fast Decoding도 함께 사용한다.
Parametric Memory와 Non-Parametric Memory
이 논문을 이해할 때 가장 중요한 관점은 두 memory의 분리다.
| Memory | 구현 | 장점 | 약점 |
|---|---|---|---|
| Parametric memory | BART parameter | language fluency와 implicit knowledge가 강하다. | 지식 업데이트와 근거 추적이 어렵다. |
| Non-parametric memory | Wikipedia dense index | 문서를 교체하거나 확장할 수 있다. | 검색 실패가 generation 품질을 제한한다. |
RAG는 두 memory를 더한다기보다, 확률적으로 결합한다. 문서 를 latent variable로 두고,
라는 형태로 해석할 수 있다.
이 식은 mixture model의 관점에서도 자연스럽다. 각 문서 가 하나의 expert이고, retriever 가 gating network처럼 작동한다. Generator는 각 expert가 제공하는 context를 바탕으로 답변 likelihood를 만든다.
실험 결과
논문은 RAG를 knowledge-intensive NLP task 전반에서 평가한다.
| Task | Dataset | 관찰 |
|---|---|---|
| Open-domain QA | Natural Questions, TriviaQA, WebQuestions, CuratedTrec | RAG가 여러 QA benchmark에서 강한 성능을 보인다. |
| Abstractive QA | MSMARCO NLG | BART보다 factual하고 구체적인 답변을 생성한다. |
| Question generation | Jeopardy | RAG-Token이 여러 문서 정보를 조합하는 데 유리하다. |
| Fact verification | FEVER | Evidence supervision 없이도 classification에 적용할 수 있다. |
논문의 핵심 결과 중 하나는 open-domain QA에서 RAG-Sequence가 Natural Questions와 TriviaQA Wiki split에서 강한 성능을 낸다는 점이다. 또한 generation task에서는 RAG가 BART-only baseline보다 더 구체적이고 factual한 문장을 생성하는 경향을 보인다.

논문 Figure 3. RAG-Token의 token별 document posterior 예시이다. 특정 책 제목을 생성할 때 관련 문서 posterior가 높아지고, 일부 token은 parametric memory만으로도 이어서 생성된다.
이 그림은 RAG의 장점을 잘 보여준다. Generator가 항상 retrieved document만 복사하는 것이 아니라, retrieved evidence와 내부 language model knowledge를 함께 사용한다.
검색 문서 수의 영향
RAG는 test time에 검색 문서 수 를 조정할 수 있다. 문서를 더 많이 가져오면 더 많은 evidence를 볼 수 있지만, 계산 비용이 증가하고 noisy document가 섞일 수도 있다.
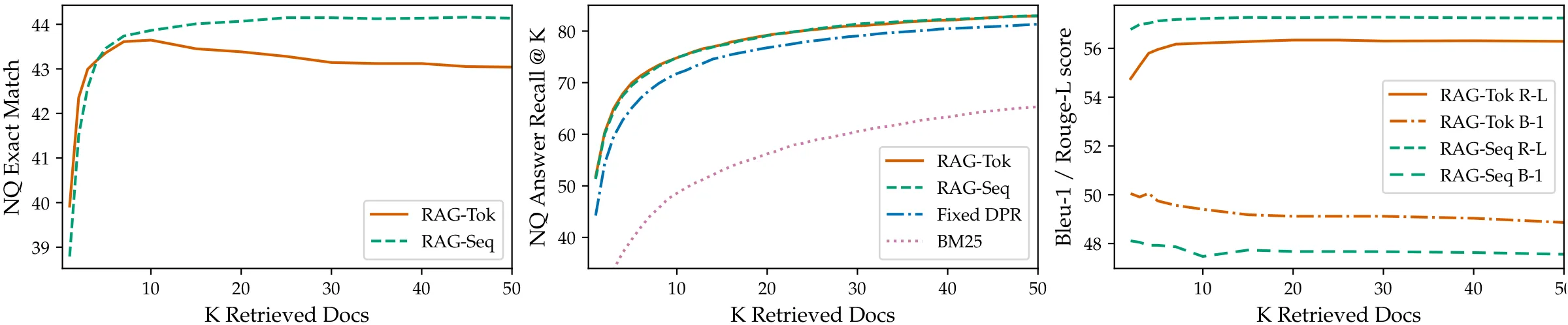
논문 Figure 4. 검색 문서 수를 늘렸을 때 QA 성능, retrieval recall, generation metric이 어떻게 바뀌는지 보여준다.
논문 결과에서는 RAG-Sequence의 open-domain QA 성능이 retrieval document 수 증가에 따라 개선되는 경향을 보인다. 반면 RAG-Token은 task에 따라 특정 이후 성능이 포화되거나 metric trade-off가 나타난다.
이는 RAG가 단순히 "문서를 많이 넣으면 된다"는 방식이 아니라는 점을 보여준다. 검색된 문서가 많아질수록 marginalization 후보는 늘어나지만, generator가 처리해야 할 noisy context도 함께 늘어난다.
한계
RAG는 이후 LLM 기반 retrieval-augmented system의 기본 형태를 만든 논문이지만, 한계도 분명하다.
-
Retriever initialization이 DPR에 의존한다. 완전히 supervision-free retrieval learning은 아니다.
-
Document encoder와 index를 고정한다. 학습 중 retrieval space 전체가 generator에 맞게 같이 바뀌지는 않는다.
-
Top- approximation을 사용한다. 실제 marginalization은 전체 문서 공간에 대한 합이지만, 계산상 상위 문서만 사용한다.
-
Retrieved document가 항상 올바른 근거라는 보장은 없다. 검색 실패가 발생하면 generator가 다시 parametric memory에 의존하거나 hallucination할 수 있다.
-
RAG는 reasoning model이라기보다 retrieval-conditioned generation model이다. 문서를 가져왔다고 해서 그 문서들 사이의 복잡한 논리 추론이 자동으로 해결되는 것은 아니다.
정리
RAG의 기여는 다음처럼 정리할 수 있다.
| 기여 | 의미 |
|---|---|
| Retrieval과 generation의 end-to-end 결합 | Retriever와 generator를 downstream likelihood로 함께 조정한다. |
| 문서 latent variable formulation | Retrieved document를 확률적으로 marginalize한다. |
| RAG-Sequence와 RAG-Token 제안 | 문서 conditioning 단위를 sequence/token으로 나누어 모델링한다. |
| Parametric/non-parametric memory 결합 | BART의 생성 능력과 Wikipedia index의 명시적 지식을 함께 사용한다. |
이 논문은 오늘날 말하는 RAG의 출발점에 가깝다. 현재의 LLM RAG system은 chunking, embedding, vector database, reranking, citation, query rewriting 등 engineering 요소가 훨씬 커졌지만, 수식의 핵심은 여전히 이 논문과 연결된다.
즉 RAG의 본질은 검색된 지식을 context로 붙이는 UI 기법이 아니라, 외부 문서를 latent knowledge source로 두고 generation probability를 marginalize하는 모델링 방식이다.