논문 정보
| 항목 | 내용 |
|---|---|
| Venue | arXiv preprint |
| 출판 시점 | 2020년 |
| 저자 | Sinong Wang, Belinda Z. Li, Madian Khabsa, Han Fang, Hao Ma |
| 소속 | Facebook AI, Seattle |
핵심 아이디어
Linformer는 Transformer의 self-attention 비용을 줄이기 위한 방법이다. 일반적인 self-attention은 sequence length를 이라 할 때 attention matrix가 이 되므로 시간과 메모리 복잡도가 모두 이다.
Linformer의 핵심 주장은 다음과 같다.
Self-attention matrix는 실제로 low-rank structure를 가지므로, Key와 Value를 sequence dimension에서 낮은 차원으로 projection해도 attention을 잘 근사할 수 있다.
즉 Query는 길이 을 유지하되, Key와 Value의 sequence length를 로 줄인다.
이렇게 하면 attention matrix를 직접 만들지 않고, attention만 계산하면 된다.
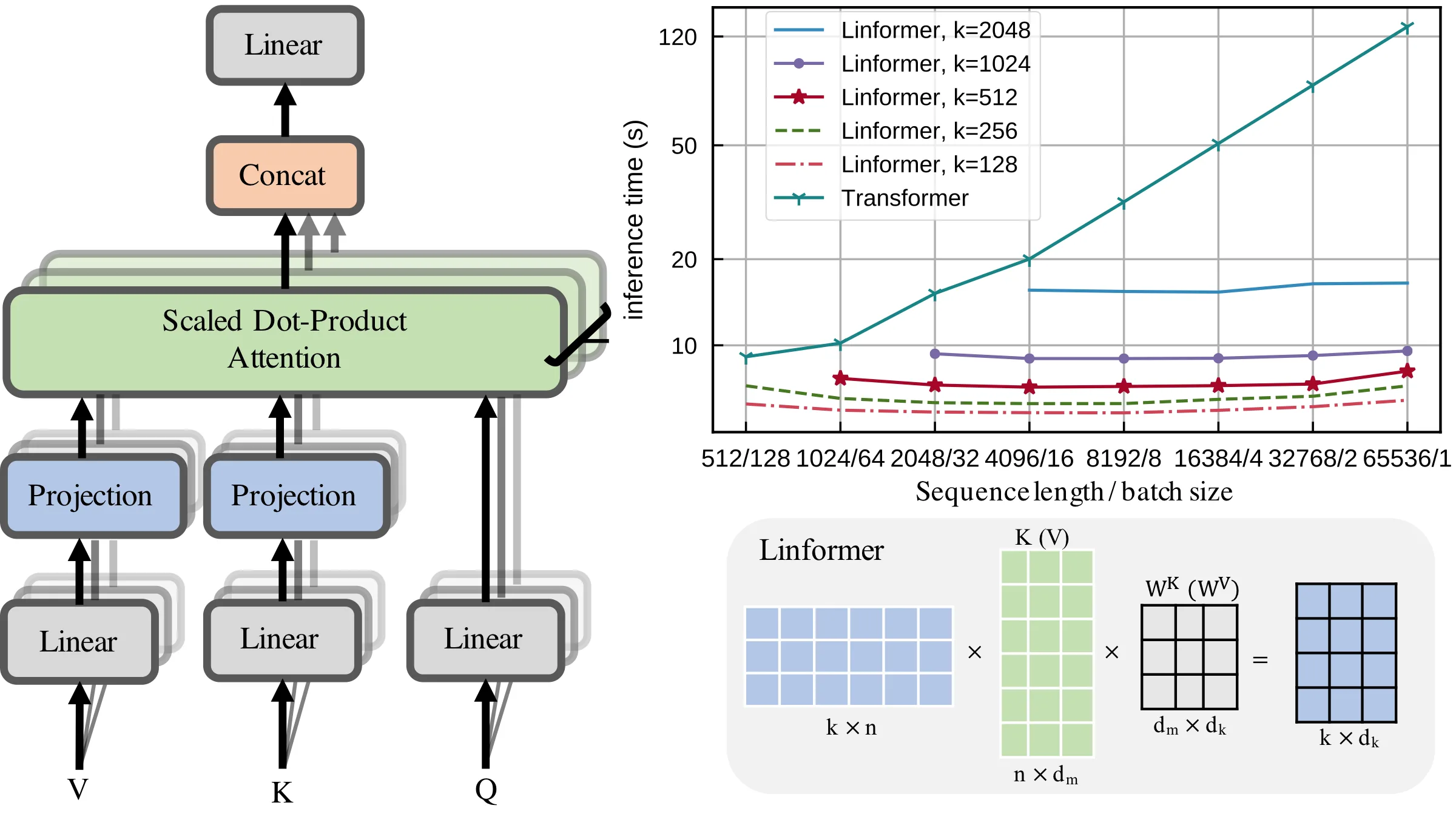
논문 Figure 2. 왼쪽은 Linformer의 linear self-attention 구조이고, 오른쪽은 sequence length가 길어질 때 Transformer와 Linformer의 inference time 차이를 보여준다.
기존 Self-Attention의 비용
입력 sequence를 라 하자. Transformer의 한 attention head는 다음처럼 Query, Key, Value를 만든다.
여기서
이다. Scaled dot-product attention은 다음과 같다.
문제는 이다.
따라서 token이 길어질수록 attention score matrix가 quadratic하게 커진다.
| 항목 | 복잡도 |
|---|---|
| Attention score 계산 | |
| Attention matrix 저장 | |
| Value와 곱셈 |
긴 문서, 긴 대화, long-context NLP에서는 이 이 병목이 된다.
Low-Rank 가정
Linformer는 attention matrix가 low-rank로 근사될 수 있다고 본다. Attention probability matrix를
라 하자. 일반 attention은 를 계산한다.
만약 가 rank 정도로 잘 근사된다면,
이다. 그러면 굳이 full attention matrix를 만들 필요가 없다.
Linformer는 이 관찰을 직접적인 SVD로 풀지 않는다. 대신 학습 가능한 projection matrix로 Key와 Value를 sequence dimension에서 압축한다.
Linformer의 Projection
일반적인 linear projection은 feature dimension을 바꾼다.
하지만 Linformer의 projection은 feature dimension이 아니라 sequence dimension을 줄인다.
기존 Key와 Value는 다음 모양이다.
여기서 은 token 개수이고, 는 head dimension이다. Linformer는 projection matrix 을 사용한다.
즉 Key와 Value의 token length가 에서 로 줄어든다. Query는 그대로 둔다.
그래서 Linformer attention은 다음처럼 계산된다.
모양을 확인하면 다음과 같다.
| 항목 | Shape |
|---|---|
| 최종 출력 |
결국 attention score matrix가 에서 로 바뀐다.
복잡도 비교
기존 self-attention은 을 계산하므로 가 필요하다. Linformer는 을 계산한다.
따라서 를 sequence length와 무관한 작은 값으로 고정하면 복잡도는 에 가까워진다.
| 방식 | Attention matrix | 시간 복잡도 | 메모리 복잡도 |
|---|---|---|---|
| Standard self-attention | |||
| Linformer |
가 고정 상수라면,
로 볼 수 있다.
이것이 제목의 linear complexity가 의미하는 바다.
Multi-Head Attention에서의 적용
기존 multi-head attention은 다음과 같다.
각 head는
이다. Linformer에서는 각 head의 Key와 Value에 projection을 적용한다.
Projection matrix 를 head마다 따로 둘 수도 있고, layer나 head 간에 공유할 수도 있다. 논문은 parameter와 memory를 줄이기 위해 다양한 sharing 전략을 실험한다.
| Sharing 방식 | 의미 |
|---|---|
| Head-wise sharing | 여러 head가 같은 projection을 공유한다. |
| Key-Value sharing | 와 를 같은 matrix로 둔다. |
| Layer-wise sharing | layer 사이에서도 projection을 공유한다. |
핵심은 projection matrix 자체도 학습 가능하다는 점이다. 즉 어떤 token 위치들을 어떻게 압축할지는 모델이 학습한다.
왜 Key와 Value만 줄이는가
Query까지 줄이면 출력 token 수가 이 아니라 가 된다. 하지만 Transformer layer는 각 입력 token에 대응하는 output representation을 만들어야 한다.
따라서 Query는 을 유지해야 한다.
Key와 Value는 "어떤 token을 참고할 것인가"에 대한 memory 역할을 하므로 압축할 수 있다. 즉 Linformer는 모든 token의 output은 유지하면서, 참고할 memory slots만 개로 줄이는 방식이다.
직관
Self-attention은 모든 token이 모든 token을 직접 본다. 하지만 실제로는 각 token이 완전히 독립적인 개의 정보를 모두 필요로 하지는 않을 수 있다.
Linformer는 sequence 전체를 개의 compressed memory로 요약한다.
그 후 각 Query token은 이 compressed memory를 attend한다.
Linformer는 attention을 없애는 것이 아니라, attention이 바라보는 Key/Value memory의 길이를 줄인다.
한계
Linformer의 장점은 명확하지만, 가정도 분명하다.
-
Attention matrix가 low-rank로 잘 근사된다는 가정이 필요하다. 모든 task와 모든 layer에서 항상 성립한다고 보기는 어렵다.
-
Projection length 를 정해야 한다. 가 너무 작으면 정보가 사라지고, 너무 크면 효율 이득이 줄어든다.
-
Sequence position을 압축하므로 fine-grained token interaction이 약해질 수 있다. 특히 정확한 위치 대응이 중요한 task에서는 손실이 생길 수 있다.
-
이후 long-context Transformer 연구에서는 sparse attention, kernel attention, recurrent memory, sliding window attention 등 다양한 대안이 등장했다. Linformer는 그중 low-rank approximation 계열의 대표적인 방법으로 보는 것이 좋다.
정리
Linformer는 self-attention의 병목을 다음 한 줄로 바꾼다.
핵심 변화는 를 sequence dimension에서 에서 로 압축하는 것이다.
| 관점 | Standard Attention | Linformer |
|---|---|---|
| Key/Value 길이 | ||
| Attention matrix | ||
| 복잡도 | ||
| 핵심 가정 | 모든 token pair를 직접 계산한다. | Attention matrix는 low-rank로 근사 가능하다. |
결국 Linformer의 메시지는 단순하다. Transformer의 강점인 attention 구조는 유지하되, long sequence에서 비싼 interaction을 low-rank projection으로 근사하자는 것이다.