논문 정보
| 항목 | 내용 |
|---|---|
| Venue | Conference on Neural Information Processing Systems (NeurIPS) |
| 출판 시점 | 2021년 |
| 저자 | Junbum Cha, Sanghyuk Chun, Kyungjae Lee, Han-Cheol Cho, Seunghyun Park, Yunsung Lee, Sungrae Park |
| 소속 | Kakao Brain, NAVER AI Lab, Chung-Ang University, NAVER Clova, Korea University, Upstage AI Research |
문제 배경
Domain Generalization(DG) 은 source domain만 보고 학습한 모델이 unseen target domain에서도 잘 동작하도록 만드는 문제다. 예를 들어 photo, cartoon, sketch 같은 여러 domain으로 학습하고, 학습에 없던 domain에서도 높은 성능을 내는 것을 목표로 한다.
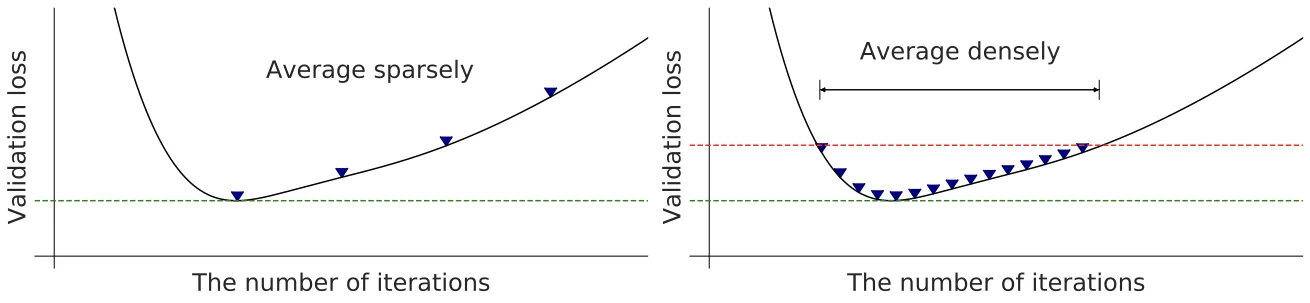
논문 Figure 2 일부. SWA는 weight를 sparse하게 평균내지만, SWAD는 validation loss가 적절한 구간에서 weight를 dense하게 평균낸다.
기존 DG 연구는 domain-invariant representation, meta-learning, data augmentation 등 다양한 방법을 제안했다.
하지만 DomainBed 같은 공정한 평가 환경에서는 단순한 ERM(Empirical Risk Minimization) 이 기존 DG 방법들과 비슷하거나 더 좋은 성능을 보이는 경우가 있었다.
이 논문은 여기서 한 단계 더 나아가, ERM 자체가 sharp minimum에 수렴하면 unseen domain generalization이 나빠질 수 있다고 본다. 그리고 flat minimum을 찾으면 domain shift에 더 robust할 수 있다고 주장한다.
핵심 주장
논문의 핵심 주장은 다음과 같다.
Domain generalization을 잘하려면 source domain의 empirical loss만 낮추는 것보다, parameter 주변에서도 loss가 낮은 flat minimum을 찾는 것이 중요하다.
이를 위해 논문은 SWAD(Stochastic Weight Averaging Densely) 를 제안한다. SWAD는 SWA를 domain generalization 상황에 맞게 바꾼 방법이다.
Domain Generalization의 수식화
source domain을 라 하고, target domain을 라 하자. DG에서는 target domain의 sample을 학습에 사용할 수 없다. 학습에서 최소화하는 source empirical risk는 다음과 같다.
목표는 target risk
를 작게 만드는 것이다. 하지만 학습 중에는 를 볼 수 없으므로, 단순히 를 줄이는 것만으로는 충분하지 않다.
논문의 관점은 다음과 같다.
가 더 좋은 DG 해를 줄 수 있다. 여기서 는 주변 perturbation까지 고려하는 robust empirical risk이다.
Robust Risk와 Flat Minimum
논문은 parameter 주변의 worst-case empirical loss를 robust empirical loss로 정의한다.
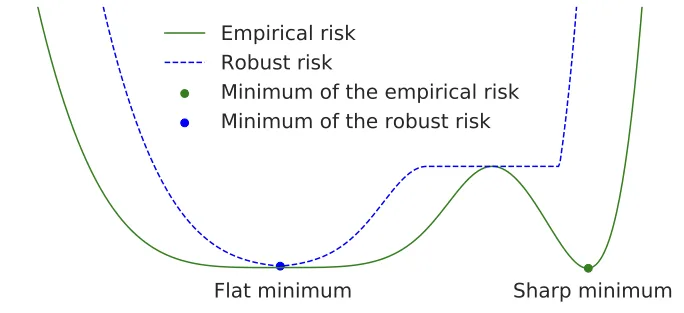
논문 Figure 1. Empirical risk만 최소화하면 sharp minimum으로 갈 수 있지만, robust risk를 최소화하면 flat minimum을 선호하게 된다.
여기서 는 parameter space에서 neighborhood의 크기를 의미한다.
이 값이 작다는 것은 주변에서 parameter가 조금 변해도 loss가 크게 증가하지 않는다는 의미다. 즉 flat minimum에 가까운 해라고 볼 수 있다.
논문은 target domain loss가 다음 요소들과 관련된 bound를 가진다고 설명한다.
| 항목 | 의미 |
|---|---|
| robust empirical loss | source domain에서 flat한 해인지 |
| domain discrepancy | source domain과 target domain의 차이 |
| confidence bound | sample 수와 hypothesis space에 따른 항 |
따라서 domain discrepancy만 줄이는 것이 아니라, flat한 해를 찾는 것도 DG 성능에 직접적으로 중요하다.
논문의 bound를 직관적으로 쓰면 다음과 같다.
여기서 는 source domain과 target domain의 분포 차이를 나타낸다.
이 식은 세 가지를 말한다.
- robust empirical loss가 작아야 한다.
- source와 target domain의 차이가 작아야 한다.
- sample 수와 hypothesis space에 따른 통계적 오차가 작아야 한다.
기존 DG 방법이 주로 2번을 줄이려 했다면, SWAD는 1번을 줄이는 쪽에 집중한다.
논문은 RRM의 최적해 에 대해 target domain gap이 다음 형태로 bound된다고 설명한다.
따라서 flat minimum을 찾는 것은 단순한 regularization trick이 아니라, DG gap을 줄이는 이론적 근거를 가진다.
SWA의 한계
SWA는 학습 trajectory에서 weight를 여러 번 sampling하고 평균내어 flat minimum을 찾는 방법이다. 하지만 DG setting에 그대로 적용하면 문제가 있다.
- DG benchmark는 학습 iteration이 상대적으로 짧아 sparse하게 sampling하면 평균낼 weight 수가 부족하다.
PACS,VLCS같은 dataset은 크기가 작아 overfitting이 빨리 발생한다.- 마지막 epoch까지 무조건 평균내면 overfitted weight까지 평균에 포함될 수 있다.
따라서 SWAD는 두 가지 수정점을 제안한다.
- Dense sampling
- Overfit-aware sampling
Dense Sampling
기존 SWA는 보통 몇 epoch마다 weight를 저장한다. SWAD는 매 iteration마다 weight를 저장하여 훨씬 촘촘하게 평균을 낸다.
고차원 parameter space에서 적은 수의 weight만 평균내면 flat minimum을 충분히 잘 근사하기 어렵다. Dense sampling은 이 문제를 줄이기 위한 선택이다.
| 방법 | Sampling 간격 |
|---|---|
| SWA | 몇 epoch마다 한 번 |
| SWAD | 매 iteration |
수식으로는 SWAD의 최종 weight를 다음처럼 쓸 수 있다.
SWA와 달리 가 epoch 단위가 아니라 iteration 단위로 조밀하게 들어간다는 점이 중요하다.
Overfit-aware Sampling
SWAD는 validation loss를 관찰하여 평균을 시작할 시점과 끝낼 시점을 정한다.
- : validation loss가 처음으로 local optimum에 도달했다고 판단되는 시점
- : validation loss가 일정 기간 동안 나빠져 overfitting이 시작됐다고 판단되는 시점
즉 SWAD는 학습 초반의 덜 학습된 weight도 제외하고, 학습 후반의 overfitted weight도 제외한다. 평균에는 적절한 구간의 weight만 포함된다.
논문에서는 이를 위해 다음 hyperparameter를 사용한다.
| Hyperparameter | 역할 |
|---|---|
| start iteration을 찾기 위한 patience | |
| end iteration을 찾기 위한 overfitting patience | |
| validation loss 증가 허용 비율 |
논문의 start iteration 조건은 다음처럼 이해할 수 있다.
즉 는 이후 구간 동안 validation loss가 더 내려가지 않는 첫 지점이다.
end iteration은 validation loss가 시작점 대비 일정 비율 이상 나빠지는 구간으로 잡는다.
이 조건은 평균 구간에 overfitted parameter가 들어오는 것을 막기 위한 장치다.
SWAD 알고리즘 직관
SWAD는 다음과 같이 이해할 수 있다.
- ERM 방식으로 모델을 학습한다.
- 매 iteration의 weight를 후보로 본다.
- validation loss를 보고 평균 시작점 를 찾는다.
- validation loss가 계속 나빠지는 시점 를 찾는다.
- 부터 사이의 weight를 평균낸다.
결과적으로 SWAD는 sharp한 한 지점이 아니라, validation loss가 좋은 구간의 중심적인 weight를 얻는다.
Flatness 분석
논문은 ERM, SAM, SWA, SWAD가 찾은 해의 flatness를 비교한다.
flatness는 parameter 주변에서 loss가 얼마나 변하는지로 측정한다.
값이 작을수록 주변 perturbation에 loss가 덜 민감하므로 더 flat하다고 볼 수 있다.
좀 더 일반적인 표기로 쓰면, 를 반지름 의 sphere에서 sampling하여
로 볼 수 있다. flat minimum이라면 같은 에 대해 이 값이 작다. sharp minimum이라면 작은 에 대해서도 loss 증가가 커진다.
실험 결과 SWAD는 ERM, SAM, 기존 SWA보다 더 flat한 minimum을 찾는다.
loss surface 시각화에서도 ERM은 flat region의 경계 근처에 있고, SWAD는 더 중심부에 위치하는 경향을 보인다.
실험 결과
논문은 PACS, VLCS, OfficeHome, TerraIncognita, DomainNet에서 SWAD를 평가한다.
평균 out-of-domain accuracy에서 SWAD는 ERM과 기존 DG 방법들보다 높은 성능을 보인다.
대표 결과는 다음과 같다.
| Method | Average out-of-domain accuracy |
|---|---|
| ERM | 63.3 |
| Best previous competitor | 65.3 |
| SWAD | 66.9 |
| Previous SOTA + SWAD | 67.3 |
SWAD는 단독으로도 성능이 좋지만, 다른 DG 방법과 결합해도 성능을 개선할 수 있다.
예를 들어 CORAL에 SWAD를 적용하면 평균 성능이 더 올라간다.
Ablation Study
논문은 SWAD의 두 요소가 모두 중요하다는 것을 ablation으로 확인한다.
| 제거한 요소 | 결과 |
|---|---|
| Dense sampling 제거 | 평균 성능이 감소한다. |
| Overfit-aware end 제거 | overfitted weight가 포함되어 성능이 감소한다. |
| Start/end를 고정 | vanilla SWA와 비슷한 수준에 머문다. |
즉 단순히 SWA를 적용하는 것보다, DG setting에 맞게 dense하고 overfit-aware하게 평균 구간을 잡는 것이 중요하다.
장점
- 기존 모델 구조나 loss function을 바꾸지 않는다.
ERM,CORAL,SAM같은 다른 방법 위에 붙일 수 있다.- model selection에 덜 민감하다.
- domain label을 강하게 사용하지 않아 다른 robustness task에도 적용 가능하다.
한계
SWAD는 flat minimum을 찾는 완전한 이론적 solver라기보다는 실용적인 heuristic에 가깝다. 또한 domain discrepancy 자체를 직접 줄이는 방법은 아니기 때문에, domain-specific information을 활용하는 방법과 결합할 여지가 있다.
실제로 논문에서도 CORAL + SWAD 조합이 좋은 성능을 보인다.
이는 flatness와 domain discrepancy를 함께 고려하는 방향이 유효할 수 있음을 보여준다.
정리
SWAD는 SWA를 domain generalization에 맞게 확장한 방법이다. 핵심은 매 iteration weight를 조밀하게 평균내되, validation loss를 기준으로 overfitting 구간을 제외하는 것이다.
이 논문은 DG 문제에서 flat minimum이 중요하다는 관점을 제시하고, 이를 간단한 weight averaging 전략으로 실현했다는 점에서 의미가 있다. 복잡한 architecture 변경 없이도 강한 성능을 보인다는 점에서 실용적인 방법이다.