논문 정보
| 항목 | 내용 |
|---|---|
| Venue | Conference on Neural Information Processing Systems (NeurIPS) |
| 출판 시점 | 2018년 |
| 저자 | Mingsheng Long, Zhangjie Cao, Jianmin Wang, Michael I. Jordan |
| 소속 | Tsinghua University, University of California, Berkeley |
핵심 아이디어
CDAN(Conditional Domain Adversarial Network) 은 unsupervised domain adaptation을 위한 adversarial learning 방법이다.
기존 DANN 계열 방법은 feature representation 만 보고 source와 target을 구분하는 domain discriminator를 학습한다.
CDAN은 여기에 classifier prediction 를 함께 넣는다.
핵심은 domain discriminator를 feature 만이 아니라, feature와 prediction의 결합 에 condition한다는 점이다.

논문 Figure 1 재구성. CDAN은 feature representation 와 classifier prediction 의 관계를 domain discriminator에 입력한다. 왼쪽은 multilinear conditioning, 오른쪽은 randomized multilinear conditioning이다.
이 논문의 문제의식은 명확하다. Domain adaptation에서 단순히 marginal feature distribution만 맞추면 class별 mode가 섞일 수 있다. 예를 들어 source의 class A feature가 target의 class B feature와 맞춰지는 mode mismatch가 생길 수 있다.
CDAN은 prediction 를 조건으로 사용하여 class-discriminative한 alignment를 유도한다.
문제 설정
Source domain은 labeled sample을 가진다.
Target domain은 unlabeled sample만 가진다.
목표는 source risk뿐 아니라 target risk도 낮은 classifier를 학습하는 것이다.
하지만 target label 는 학습 중에 주어지지 않는다. 따라서 source classification loss를 줄이면서, source와 target의 representation distribution discrepancy를 줄여야 한다.
DANN의 기본 구조
먼저 DANN을 수식으로 보자.
Feature extractor를 , classifier를 , domain discriminator를 라 하자.
Classifier는 source label에 대해 cross entropy를 최소화한다.
Domain discriminator는 feature가 source인지 target인지 맞추려고 한다. 반대로 feature extractor는 discriminator가 source와 target을 구분하지 못하도록 학습된다.
단순화하면 minimax objective는 다음과 같다.
이때 DANN은 주로 를 사용한다.
즉 feature만 보고 domain alignment를 수행한다.
왜 Feature만 맞추면 부족한가
Classification problem의 feature distribution은 보통 multimodal하다. 각 class가 하나의 mode를 형성하기 때문이다.
Feature marginal만 맞추는 것은 다음 분포를 맞추는 것에 가깝다.
하지만 실제로 필요한 것은 class conditional structure가 보존된 alignment이다.
Target에는 label이 없으므로 를 직접 사용할 수 없다. CDAN은 대신 classifier prediction 를 사용한다. Prediction 는 soft label처럼 작동하면서 feature가 어느 class mode에 속하는지에 대한 정보를 준다.
즉 CDAN은 다음과 같은 joint structure를 맞추려 한다.
이 관점에서 CDAN은 단순 feature alignment가 아니라 conditional adversarial alignment이다.
Multilinear Conditioning
CDAN의 가장 중요한 수식은 multilinear map이다. Feature 와 prediction 가 있을 때, CDAN은 두 벡터의 outer product를 사용한다.
이 값은 dimension이 인 벡터로 볼 수 있다. 원소 단위로 쓰면 다음과 같다.
이 식의 의미는 단순 concat과 다르다. Concat은 와 를 나란히 붙일 뿐이다.
반면 outer product는 feature dimension과 class prediction dimension의 interaction을 만든다. Prediction 가 class 에 대한 soft assignment라면, 는 feature 가 class mode에서 얼마나 중요한지 표현한다.
Multilinear conditioning은 feature와 class prediction 사이의 cross-covariance structure를 domain discriminator가 보게 만든다.
Randomized Multilinear Conditioning
Outer product는 강력하지만 dimension이 커진다.
예를 들어 , 라면 dimension이 된다. 이 값을 그대로 discriminator에 넣으면 parameter 수가 과도하게 커진다.
그래서 논문은 randomized multilinear map을 사용한다.
여기서 , 는 random matrix이고, 는 element-wise product이다.
핵심은 inner product 보존이다.
즉 는 의 interaction을 더 낮은 dimension에서 근사한다. 논문은 이면 full multilinear map을 쓰고, 그보다 크면 randomized map을 사용한다.
CDAN Objective
CDAN의 adversarial loss는 domain discriminator가 를 보고 source와 target을 구분하도록 만든다. 단순화하면 다음과 같다.
여기서
이고 target도 동일하게 정의한다.
전체 학습은 다음 minimax problem으로 볼 수 있다.
Gradient reversal layer 관점에서는 는 domain classification을 잘하도록 학습되고, 는 domain classification을 어렵게 만드는 방향으로 update된다.
Entropy Conditioning
Prediction 를 조건으로 쓰는 것은 강력하지만 위험도 있다. Target sample에 대한 prediction이 불확실하면, 그 prediction을 condition으로 쓰는 것이 오히려 alignment를 망칠 수 있다.
논문은 이 문제를 entropy로 다룬다. Prediction entropy는 다음과 같다.
확실한 prediction은 entropy가 낮고, 불확실한 prediction은 entropy가 높다. CDAN+E는 entropy-aware weight를 사용한다.
Entropy가 낮으면 가 크므로 weight가 커진다. Entropy가 높으면 weight가 작아진다.
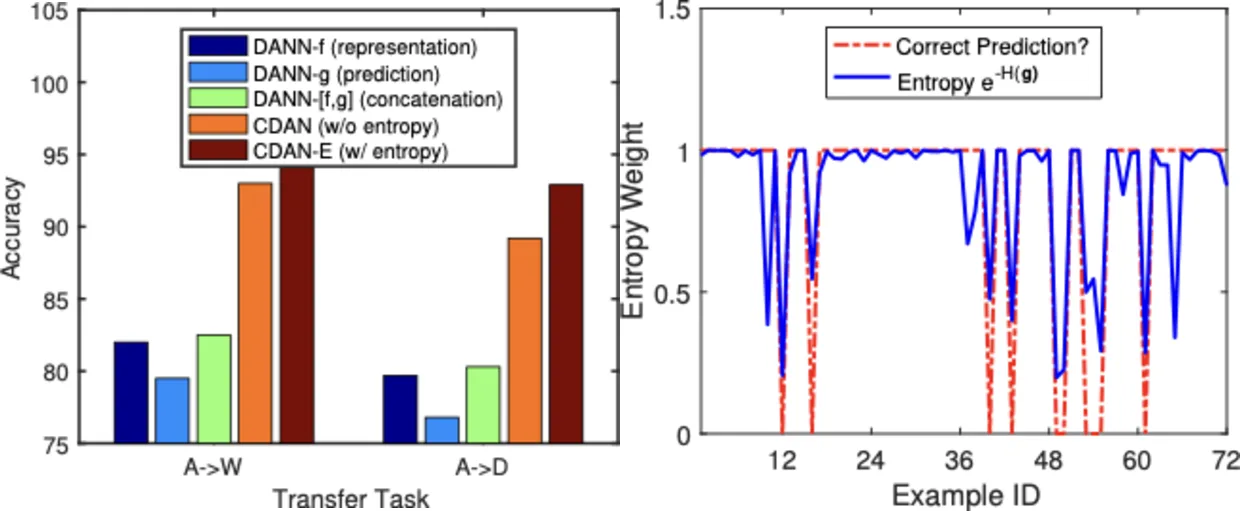
논문 Figure 2 일부. Multilinear conditioning과 entropy conditioning은 단순 concat 또는 feature-only discriminator보다 더 나은 alignment를 보인다.
Entropy conditioning은 confident한 sample을 더 강하게 사용하고, 불확실한 sample의 부정확한 pseudo-label 효과를 줄인다.
이론적 관점
Domain adaptation bound는 target risk가 source risk와 domain discrepancy에 의해 제한된다는 형태를 가진다. 직관적으로 쓰면 다음과 같다.
CDAN은 여기서 discrepancy를 feature marginal이 아니라 joint proxy distribution 위에서 본다. Classifier prediction을 사용하여 다음 proxy를 만든다.
이제 discrepancy는 와 사이에서 측정된다. Domain discriminator가 를 구분하지 못하게 만들면, 이 joint proxy distribution의 차이를 줄이는 방향으로 학습된다.
즉 CDAN의 이론적 핵심은 다음과 같다.
| 방법 | 줄이려는 discrepancy |
|---|---|
| DANN | 와 의 차이 |
| CDAN | 와 의 차이 |
후자가 class-discriminative structure를 더 잘 보존할 가능성이 높다.
실험 결과
논문은 Office-31, ImageCLEF-DA, Office-Home, Digits, VisDA-2017에서 CDAN을 평가한다.
Backbone은 AlexNet과 ResNet-50을 사용한다.
대표적인 관찰은 다음과 같다.
| 실험 | 관찰 |
|---|---|
| Office-31 | CDAN+E가 대부분의 transfer task에서 강한 성능을 보인다. |
| Office-Home | domain 차이가 큰 setting에서도 기존 방법보다 좋은 평균 성능을 보인다. |
| Digits / VisDA | feature-level adaptation임에도 여러 benchmark에서 안정적으로 동작한다. |
| Ablation | concat보다 multilinear conditioning이 좋고, entropy conditioning이 추가 성능을 만든다. |
특히 논문은 DANN-[f,g]처럼 단순 concat을 하는 방법이 충분하지 않다고 분석한다.
Concat은 와 의 interaction을 직접 만들지 못하기 때문이다.
장점
- 기존 adversarial domain adaptation에 prediction conditioning을 추가하는 비교적 단순한 구조이다.
- Multilinear conditioning으로 class-aware alignment를 유도한다.
- Randomized multilinear map으로 dimension explosion을 줄인다.
- Entropy conditioning으로 uncertain target sample의 악영향을 완화한다.
- 여러 domain adaptation benchmark에서 강한 성능을 보인다.
한계
CDAN은 classifier prediction 에 의존한다. 초기 prediction이 매우 틀리거나 target domain이 source와 지나치게 다르면, 잘못된 class structure를 기준으로 alignment할 위험이 있다.
또한 adversarial training 자체의 불안정성은 남아 있다. Discriminator가 너무 강하거나 약하면 feature extractor가 적절한 alignment signal을 받지 못할 수 있다. Randomized multilinear map도 효율적이지만, random projection dimension 선택에 따라 근사 품질과 계산량이 달라진다.
정리
CDAN은 domain adaptation에서 중요한 질문을 던진다. 단순히 feature distribution을 맞추는 것으로 충분한가?
이 논문의 답은 아니다. Classification에서는 feature distribution이 class별 mode를 가지므로, feature와 prediction의 결합 분포를 맞추는 것이 더 자연스럽다.
수식적으로 CDAN의 핵심은 를 로 바꾸는 것이다. 이 작은 변화가 domain discriminator에게 class-aware한 정보를 제공하고, multimodal distribution alignment를 더 잘 수행하게 만든다.