논문 링크: U-Net: Convolutional Networks for Biomedical Image Segmentation
논문 정보
| 항목 | 내용 |
|---|---|
| Venue | Medical Image Computing and Computer-Assisted Intervention (MICCAI) |
| 출판 시점 | 2015년 |
| 저자 | Olaf Ronneberger, Philipp Fischer, Thomas Brox |
| 소속 | Computer Science Department and BIOSS Centre for Biological Signalling Studies, University of Freiburg |
핵심 아이디어
U-Net은 biomedical image segmentation을 위해 제안된 fully convolutional network이다. 핵심은 단순히 encoder로 feature를 압축하는 것이 아니라, contracting path에서 얻은 고해상도 feature를 expanding path로 직접 전달한다는 점이다.
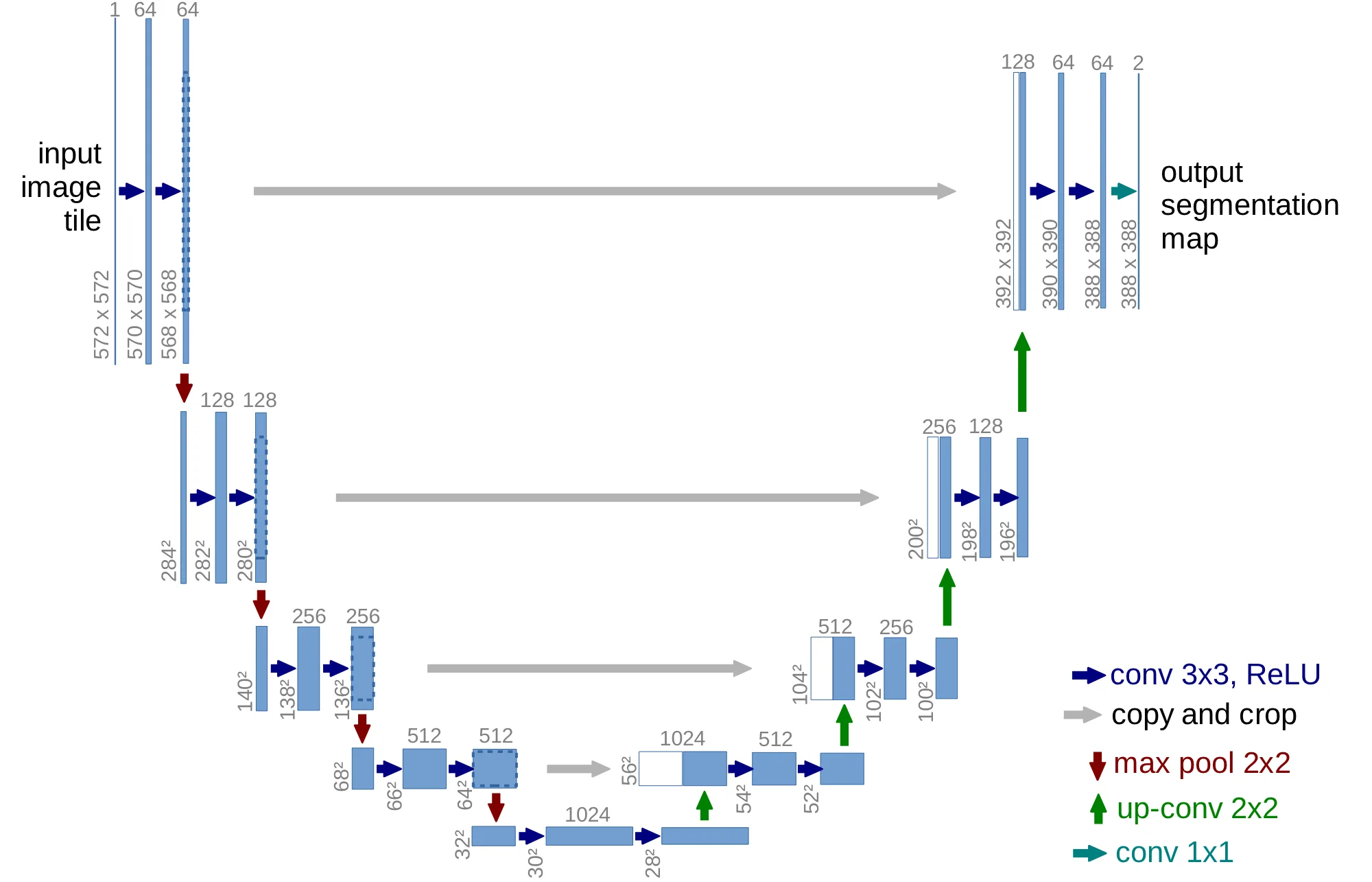
논문 Figure 1. 왼쪽 contracting path는 context를 추출하고, 오른쪽 expanding path는 localization을 복원한다. 같은 해상도의 feature map을 crop해서 concat하는 skip connection이 핵심이다.
일반적인 classification network는 입력 이미지 전체에 대해 하나의 label을 예측한다. 반면 segmentation은 각 pixel마다 class를 예측해야 한다. 즉 입력이 image라면 출력은 scalar label이 아니라 다음과 같은 dense prediction이다.
여기서 는 class 수이다. U-Net은 이 dense prediction을 patch-wise sliding window 없이 end-to-end로 수행한다.
문제 배경
Biomedical segmentation에서는 보통 다음 문제가 동시에 나타난다.
| 문제 | 의미 |
|---|---|
| 적은 annotation | 의료/생물 이미지는 pixel-level label을 만들기 어렵다. |
| 정확한 localization | 세포 경계처럼 작은 위치 차이가 중요하다. |
| 넓은 context | 한 pixel을 판단하려면 주변 조직 구조를 함께 봐야 한다. |
| 큰 이미지 | 현미경 이미지는 GPU memory보다 클 수 있다. |
기존 sliding-window 방식은 pixel마다 patch를 잘라 network를 실행한다. 이 방법은 localization은 가능하지만, 겹치는 patch가 많아 계산이 느리고 context와 localization 사이에 trade-off가 생긴다.
U-Net은 이 문제를 encoder-decoder 구조와 skip connection으로 해결한다.
Architecture
U-Net은 크게 두 부분으로 나뉜다.
- Contracting path
- Expanding path
Contracting path는 일반적인 CNN처럼 동작한다.
각 단계에서 두 번의 3x3 convolution + ReLU를 적용하고, 2x2 max pooling으로 resolution을 줄인다.
resolution이 줄어드는 대신 channel 수는 증가하므로 network는 더 넓은 context를 볼 수 있다.
Expanding path는 반대로 resolution을 키운다.
각 단계에서 up-convolution을 통해 feature map을 크게 만들고, contracting path의 같은 level feature를 가져와 concat한다.
수식적으로 한 level의 decoder feature를 단순화하면 다음처럼 볼 수 있다.
여기서 은 encoder의 번째 feature map이고, 은 decoder의 번째 feature map이다. 은 convolution과 nonlinearity를 묶은 함수이다.
이 식에서 중요한 부분은 concat이다.
Decoder는 upsampling만으로 세밀한 위치 정보를 복원하지 않는다.
대신 encoder의 고해상도 feature를 직접 받아서 localization을 보완한다.
Skip Connection의 의미
U-Net의 skip connection은 ResNet의 residual connection과 목적이 다르다. ResNet은 gradient flow와 residual learning이 핵심이고, U-Net은 encoder에서 사라지기 쉬운 위치 정보를 decoder에 다시 공급하는 것이 핵심이다.
| 연결 방식 | 주된 목적 |
|---|---|
| ResNet residual | 깊은 network의 optimization을 돕는다. |
| U-Net skip connection | segmentation boundary와 위치 정보를 복원한다. |
Pooling을 여러 번 거치면 feature는 semantic하게 풍부해지지만 spatial precision은 낮아진다. 세포 경계처럼 작은 구조를 segment하려면 shallow layer의 위치 정보가 중요하다. 그래서 U-Net은 같은 scale의 encoder feature를 decoder에 연결한다.
Pixel-wise Softmax와 Loss
U-Net의 마지막 layer는 각 pixel 위치 에서 class별 activation 를 출력한다. 논문은 pixel-wise softmax를 다음과 같이 정의한다.
각 pixel의 정답 label을 라 하면, 기본 cross entropy는 다음과 같다.
하지만 biomedical segmentation에서는 class imbalance와 touching object 문제가 크다. 배경 pixel이 많고, 붙어 있는 세포 사이의 얇은 경계는 매우 적다. 그래서 논문은 pixel-wise weight map 를 도입한다.
즉 모든 pixel을 같은 중요도로 보지 않고, 경계처럼 어려운 pixel에 더 큰 weight를 준다.
Weight Map
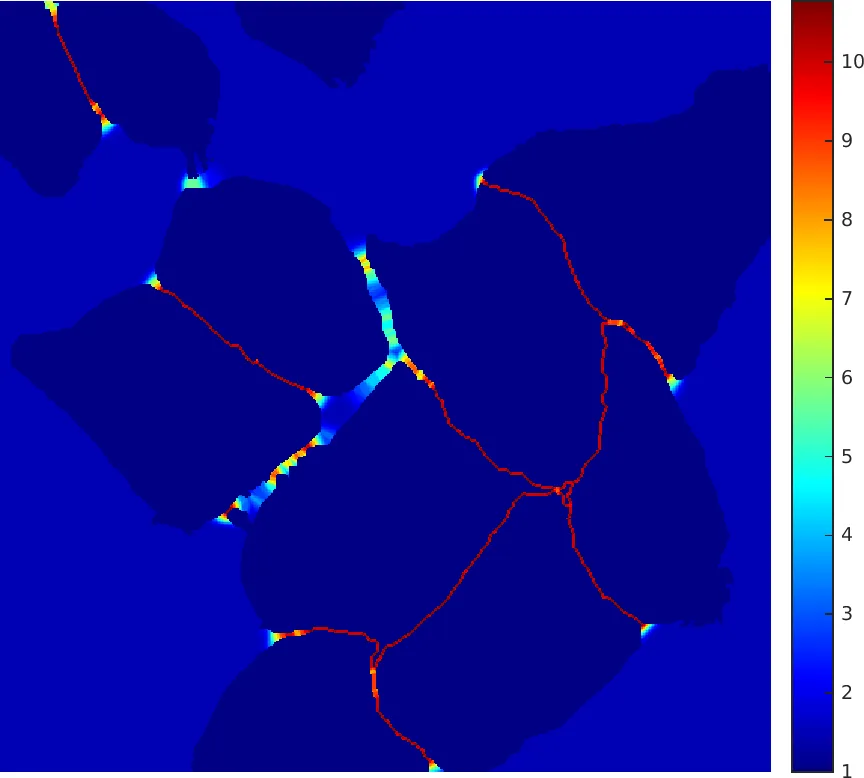
논문 Figure 3(d). Weight map은 붙어 있는 cell 사이의 경계를 더 강하게 학습하도록 만든다.
논문에서 사용하는 weight map은 다음과 같다.
각 항의 의미는 다음과 같다.
| 항 | 의미 |
|---|---|
| class frequency imbalance를 보정한다. | |
| 가장 가까운 cell boundary까지의 거리이다. | |
| 두 번째로 가까운 cell boundary까지의 거리이다. | |
| boundary 강조 강도를 조절한다. | |
| boundary 강조가 퍼지는 폭을 조절한다. |
가 작다는 것은 두 cell boundary 사이에 있는 pixel이라는 뜻이다. 즉 서로 붙어 있는 object 사이의 좁은 배경 영역에 큰 weight가 부여된다.
U-Net의 loss 설계는 단순히 pixel accuracy를 올리는 것이 아니라, instance 사이의 분리 경계를 강하게 학습하도록 만든다.
Overlap-tile Strategy
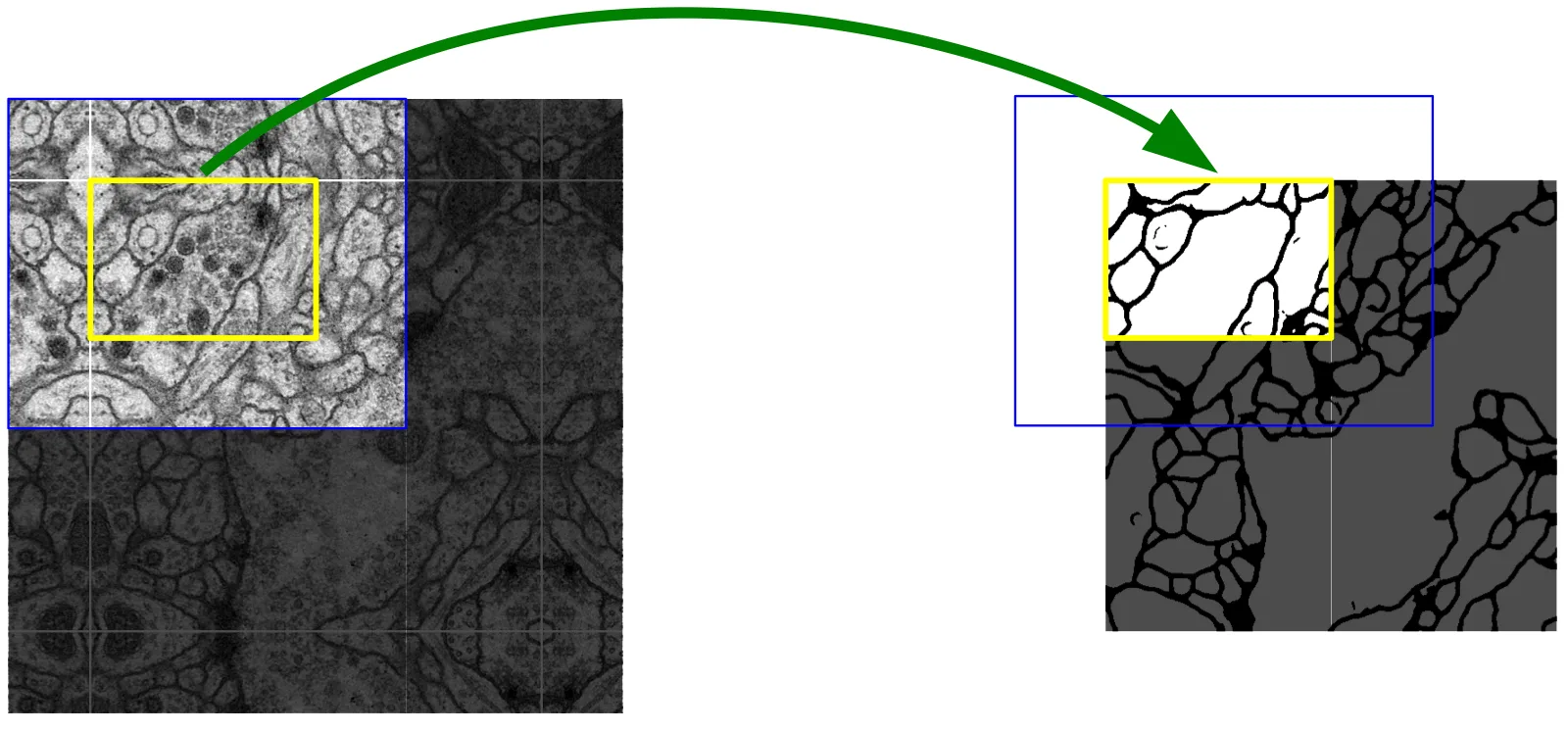
논문 Figure 2. 큰 이미지를 겹치는 tile로 나누어 예측하고, 경계 영역의 부족한 context는 mirroring으로 보완한다.
U-Net은 padding 없는 valid convolution을 사용한다.
따라서 입력 tile보다 출력 segmentation map이 작다.
예를 들어 논문 구조에서는 입력에서 출력이 나온다.
이 선택에는 이유가 있다. Padding을 넣으면 image boundary에서 실제로 존재하지 않는 값이 network에 들어간다. Biomedical image에서는 이런 boundary artifact가 segmentation 품질을 망칠 수 있다.
큰 이미지를 처리할 때는 전체 이미지를 한 번에 GPU에 올리지 않고 tile 단위로 처리한다. 다만 출력할 영역 주변의 context가 필요하므로 tile을 겹치게 자른다. 이미지 바깥쪽 context는 mirroring으로 보완한다.
Data Augmentation
논문이 강조하는 또 하나의 축은 strong data augmentation이다. Biomedical image는 labeled sample이 적기 때문에 architecture만으로는 부족하다.
특히 논문은 elastic deformation을 중요하게 본다. 현미경 이미지에서 조직과 세포는 비선형적으로 변형될 수 있으므로, deformation invariance가 필요하다.
Augmentation을 함수 로 쓰면 학습 objective는 다음처럼 이해할 수 있다.
여기서 는 rotation, shift, gray value variation, elastic deformation 같은 transformation distribution이다. 즉 적은 원본 image에서 다양한 변형 sample을 생성하여 invariance를 학습한다.
실험 결과
논문은 U-Net을 ISBI neuronal structure segmentation challenge와 ISBI cell tracking challenge에 적용한다. 핵심 결과는 다음과 같다.
| 실험 | 관찰 |
|---|---|
| EM segmentation | 기존 sliding-window CNN보다 좋은 warping error를 보인다. |
| Cell tracking challenge | PhC-U373, DIC-HeLa dataset에서 큰 margin으로 좋은 성능을 보인다. |
| 속도 | image segmentation을 GPU에서 1초 이내로 수행한다. |
결과가 중요한 이유는 단순히 score가 높아서가 아니다. U-Net은 많은 labeled image가 없더라도, architecture와 augmentation을 결합하면 biomedical segmentation을 실용적으로 풀 수 있음을 보여준다.
장점
- Dense prediction을 end-to-end로 수행한다.
- Skip connection으로 context와 localization을 함께 사용한다.
- Pixel-wise weight map으로 touching object boundary를 잘 학습한다.
- Overlap-tile strategy로 큰 이미지도 처리할 수 있다.
- 이후 medical image segmentation architecture의 기본 template이 되었다.
한계
U-Net은 2015년 기준으로 매우 강력했지만, 모든 문제를 해결하는 구조는 아니다. 원 논문 구조는 attention, transformer, pretrained backbone 같은 최근 요소를 사용하지 않는다. 또한 weight map 설계는 biomedical instance separation에는 유용하지만, 문제마다 직접 설계가 필요할 수 있다.
Skip connection도 항상 좋은 것만은 아니다. Low-level feature가 noisy한 경우 decoder가 불필요한 texture에 민감해질 수 있다. 따라서 현대 segmentation model에서는 attention gate, normalization, residual block, transformer encoder 등을 결합하여 변형하는 경우가 많다.
정리
U-Net은 segmentation 문제에서 context와 localization을 동시에 잡는 구조적 해법을 제시했다. 수식적으로 보면 pixel-wise classification 문제를 풀지만, architecture 관점에서는 encoder의 semantic feature와 shallow spatial feature를 결합하는 방식이 핵심이다.
이 논문의 의의는 단순한 U자형 그림에 있지 않다. 적은 annotation, 정확한 boundary, 큰 이미지 처리라는 biomedical segmentation의 현실적인 제약을 하나의 training pipeline으로 묶었다는 점이 중요하다.