https://github.com/kar7mp5/SurvivalRL
동기는 개인적인 견해이기 때문에 스킵하고 보셔도 무방합니다.
동기
이전에 유전 알고리즘(Genetic Algorithm)으로 생태계 구현해봤을 때 여러 아쉬운 점이 있었습니다.
간단히 소개하면, 속도, 크기 값이 부모 유전자와 돌연변이를 통해 다음 세대로 전달되는 시뮬레이션이었습니다.
유전 알고리즘(Genetic Algorithm)이 아닌 강화학습(Reinforcement Learning)으로 구현하고 싶었던 점과 학습하는 객체에 더 많은 변수가 있는 환경을 만들고 싶었습니다.
시뮬레이션 도구 고민
시뮬레이션 도구는 여러 개 있습니다. 게임엔진 Unity, Unreal, Godot 부터 다양한 언어들의 게임엔진 도구들이 많습니다.
저의 needs는 두 개 였습니다. 1. 시뮬레이션이 가능한지 2. 그래프 삽입에 유용한지 였습니다.
그래서 고민 끝에 나온 도구가 Python의 matplotlib이었습니다.
시뮬레이션 정의
간단한 생태계 구현을 목적으로 시뮬레이션 제작했습니다. 그래서 다음과 같은 객체를 구상했습니다.
시뮬레이션 조건
객체
- 식물: 스스로 에너지를 얻으며 자연분열
- 초식 동물: 식물 섭취로 에너지를 얻으며 무성생식
- 육식 동물: 식물과 초식동물 포식으로 에너지를 얻으며 무성생식
시뮬레이션 구현 - 물리엔진(충돌 시스템)
matplotlib으로 구현하다보니 충돌 시스템부터 구현해야 했습니다.
처음에 Euclidean distance 기반으로 구현 시도했습니다. 그런데 객체가 10개를 넘어서자 시뮬레이션 실행속도가 너무 느려졌습니다.
해결방안으로 AABB(Axis-aligned minimum bounding box)로 먼저 Collision 탐지가 되면, Euclidean distance로 진짜 충돌했는 지 검사했습니다. 추가적으로 전체 맵을 Grid로 작게 나눠서 같은 Grid에 있는 객체끼리만 충돌 검사를 진행했습니다.
AABB + Euclidean 충돌 탐지
자세히 보면 Circle 객체끼리는 충돌 감지를 잘하지만 Rectangle 객체는 정확하지 않습니다.
이를 GJK(Gilbert-Johnson-Keerthi distance)알고리즘으로 해결했습니다. 제가 다루는 객체들은 모두 Convex하기 때문에 이 알고리즘 적용이 가능했습니다.
이 알고리즘은 매우 무겁기 때문에 AABB -> GJK 순으로 설계했습니다.
AABB + Euclidean + GJK 충돌 알고리즘 도입
객체가 Circle뿐만 아니라 Rectangle일 경우 충돌 감지가 정확하지 않은 문제가 있었습니다. 특히 회전이 발생하면 AABB만으로는 오차가 커집니다.
그래서 Convex 객체 간 충돌을 정확하게 판별하기 위해 Gilbert–Johnson–Keerthi (GJK) 알고리즘을 도입했습니다. 다만 GJK는 무거운 알고리즘이라 AABB → GJK 순으로 필터링을 적용하여 성능을 유지했습니다.
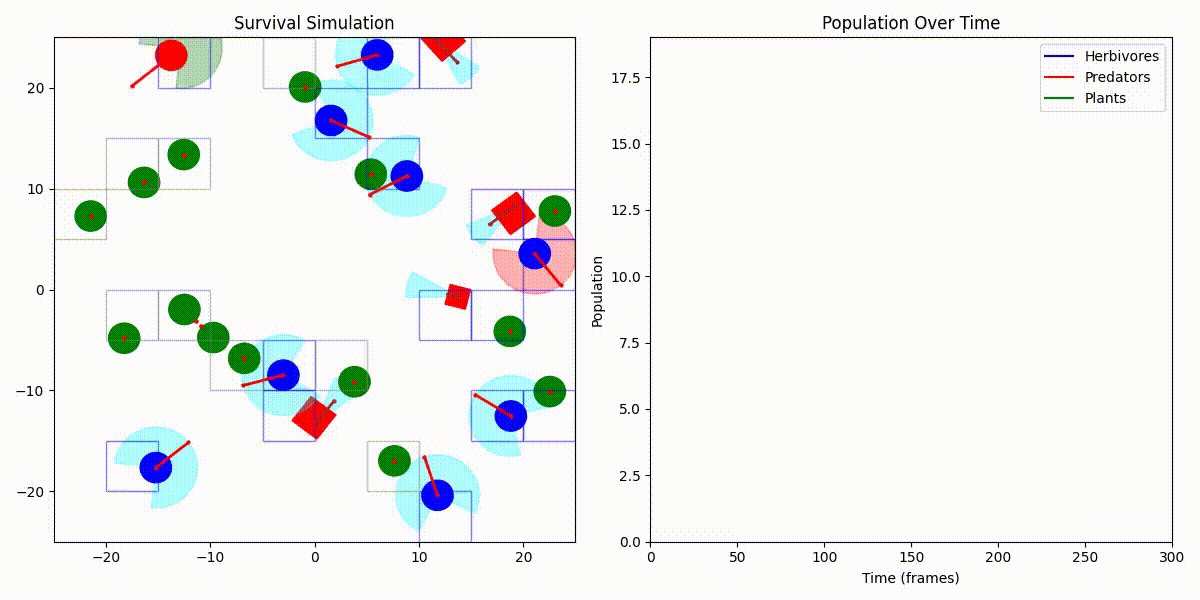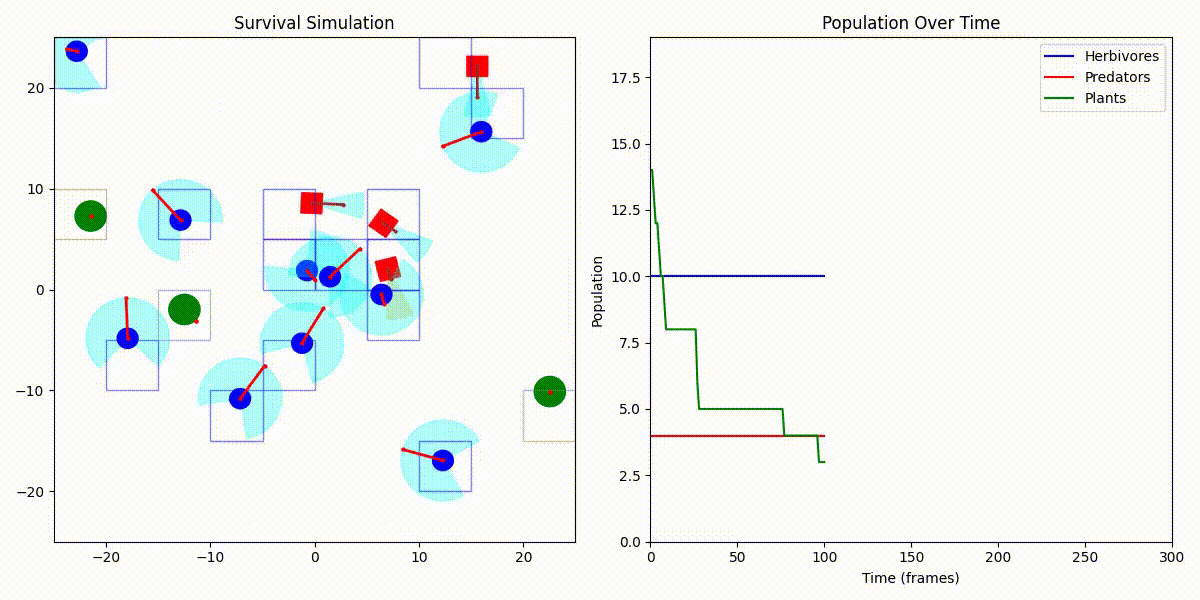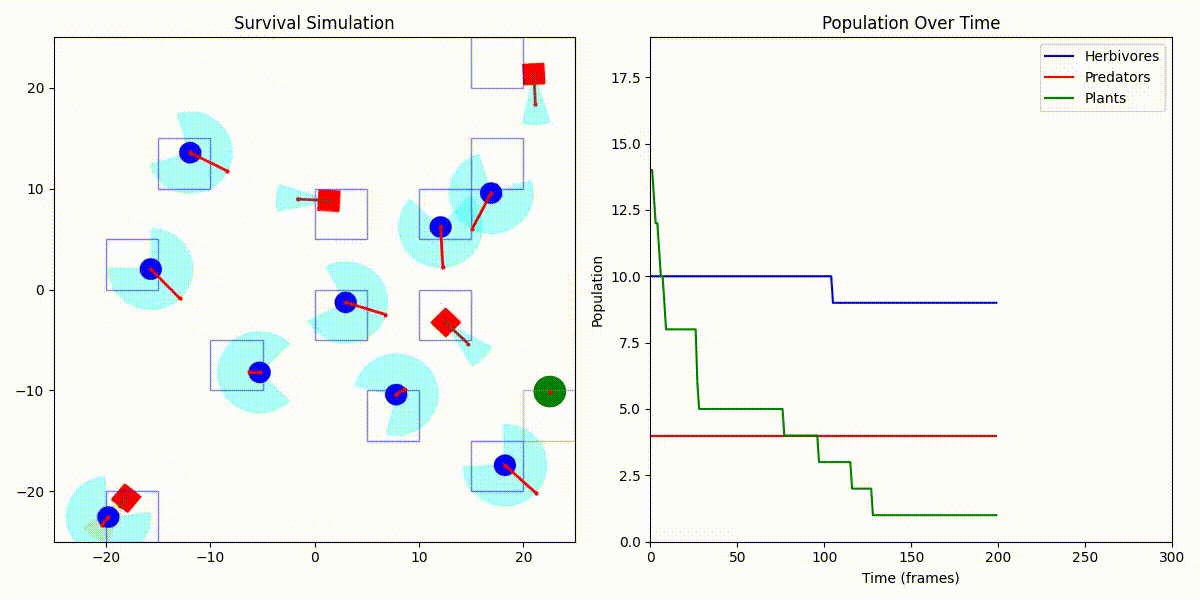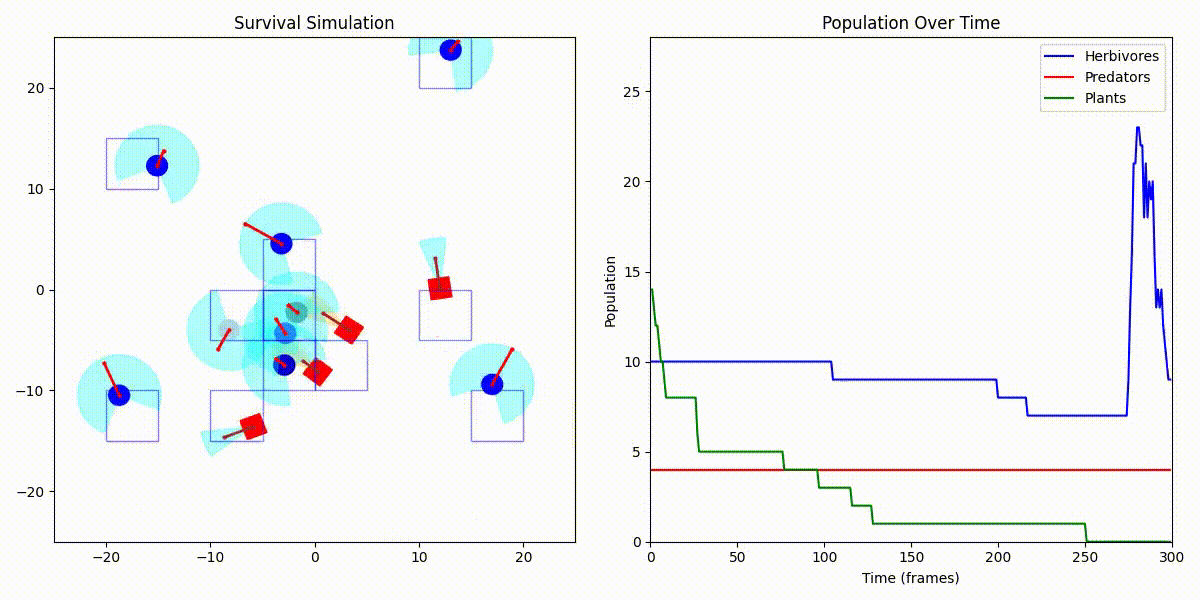
디버그 모드 + 인구 그래프
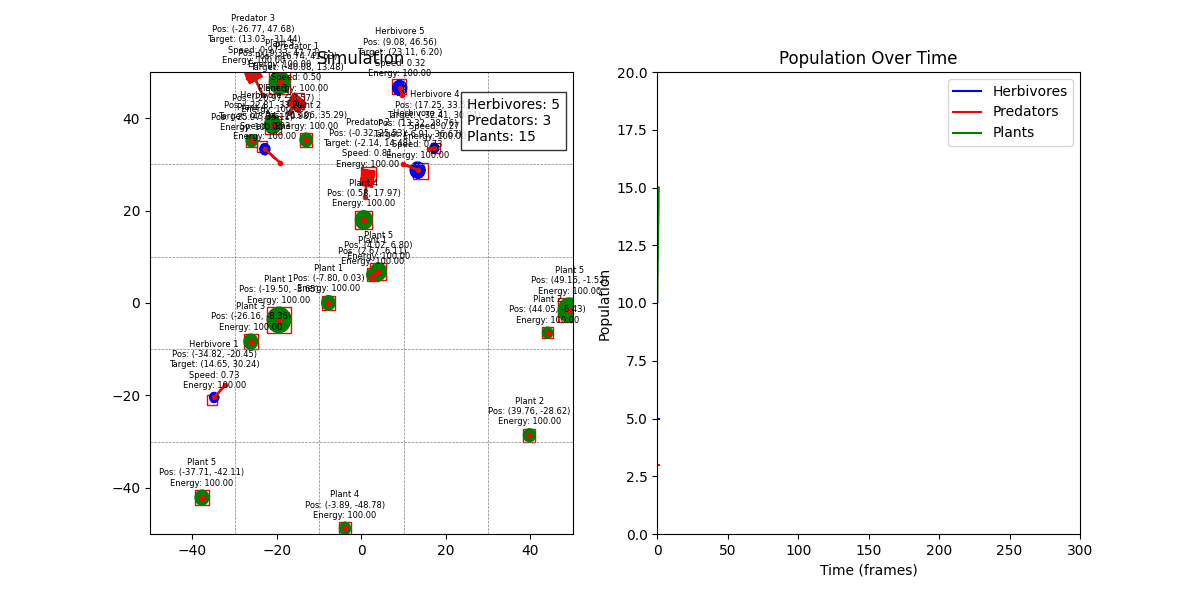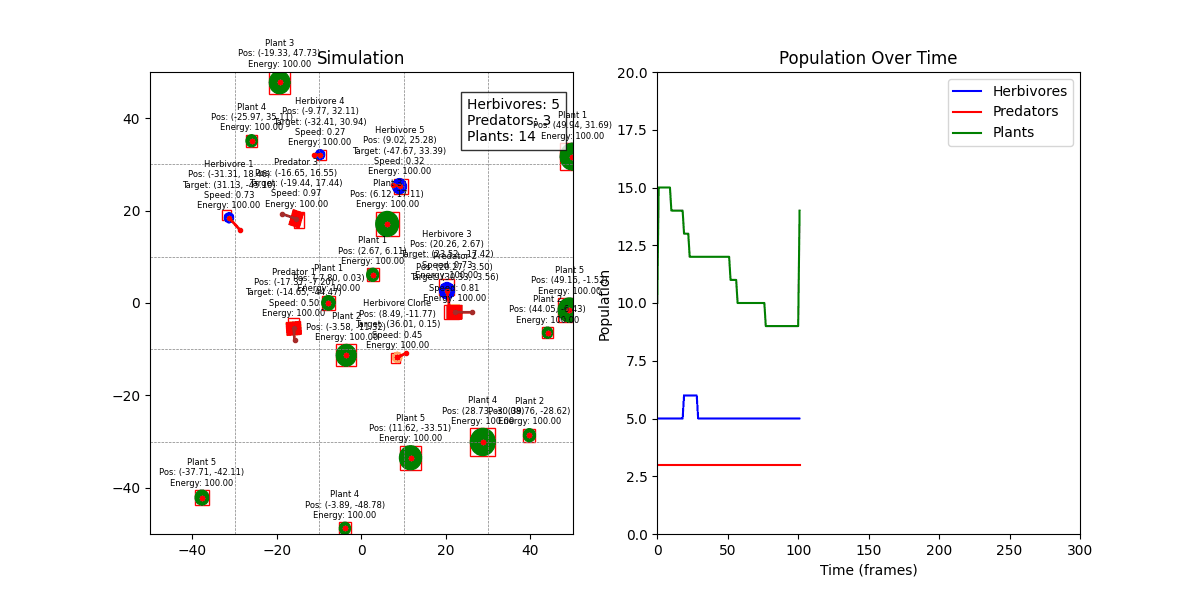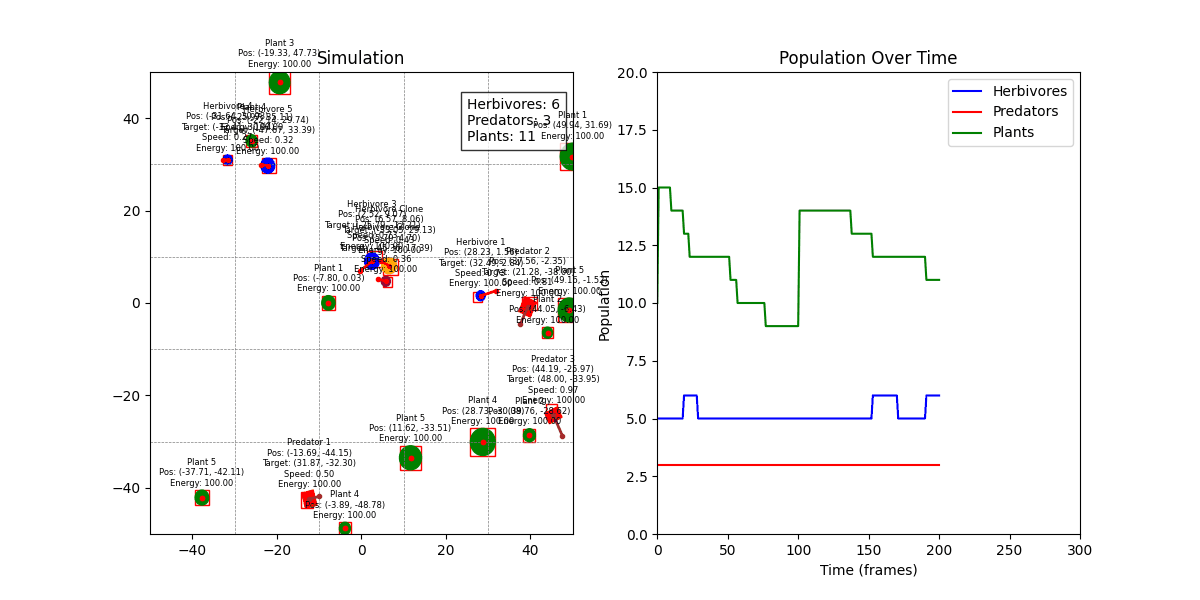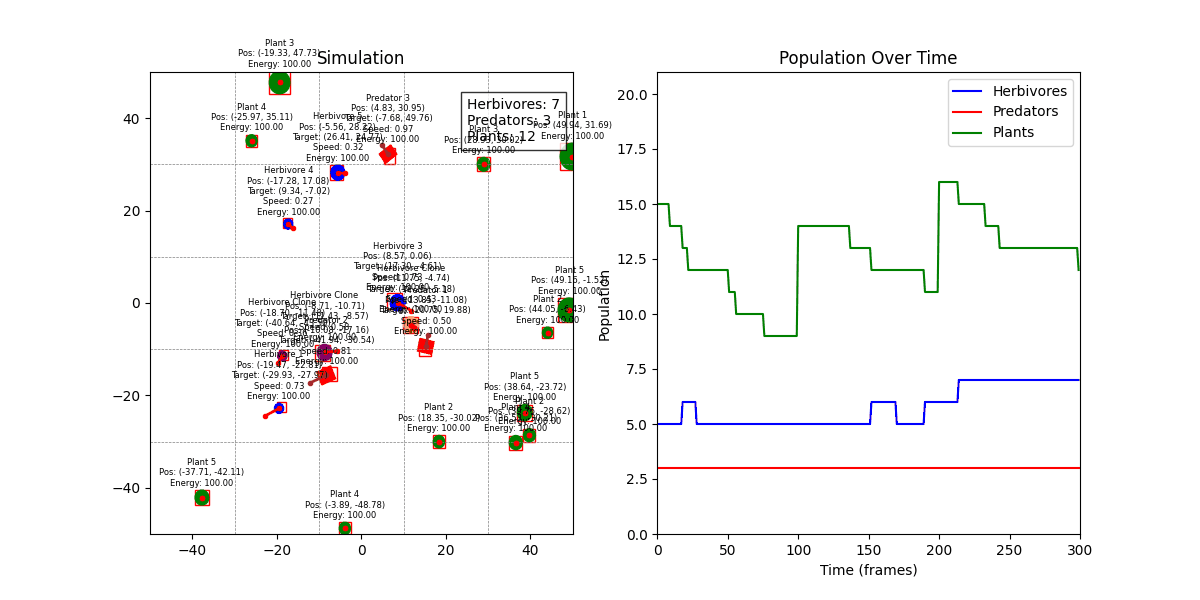
Spatial Hash Grid 기반 충돌 감지
처음에는 쿼드트리(QuadTree)를 사용했지만, FOV(시야각) 기반 탐지가 정확하지 않았습니다. 이유는 다음과 같습니다:
- 쿼드트리는 사각형 분할이기 때문에 객체가 여러 노드에 걸치면 누락되거나 중복 탐지 가능성 존재
- FOV는 방향성과 각도를 갖는 탐색이므로 정적인 공간 분할 구조와 충돌
결론적으로 Spatial Hash Grid가 더 적합했습니다. 이 방식은:
- 주변 셀만 탐색하여 성능 효율성 확보
- 이후 각도 기반 FOV 필터링 적용 가능
- 실시간 갱신, 삽입, 삭제가 단순
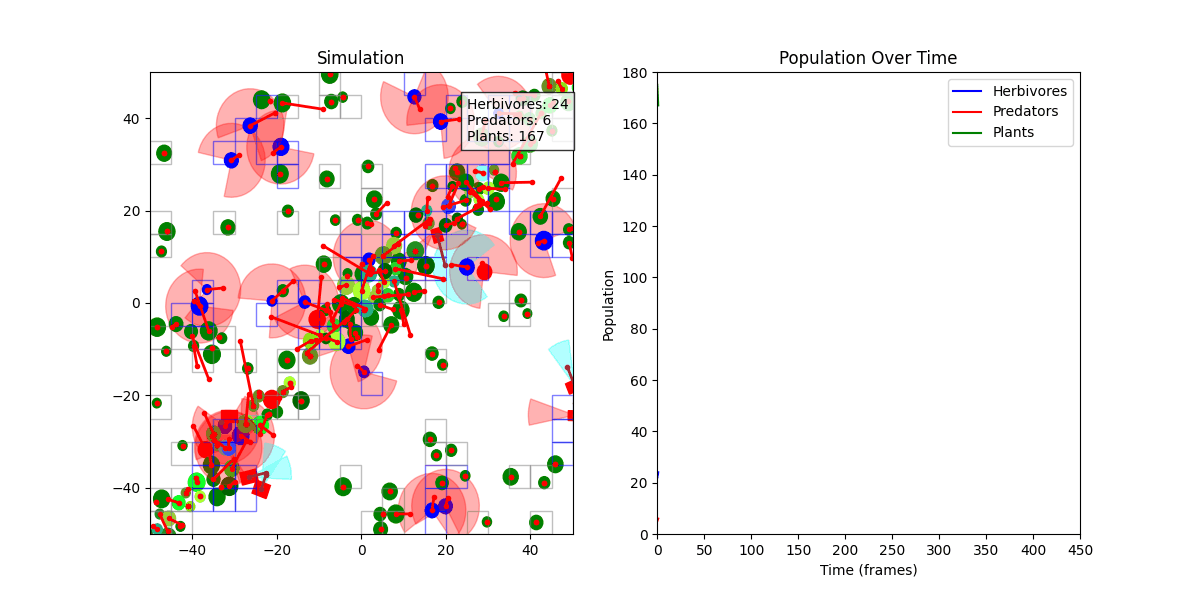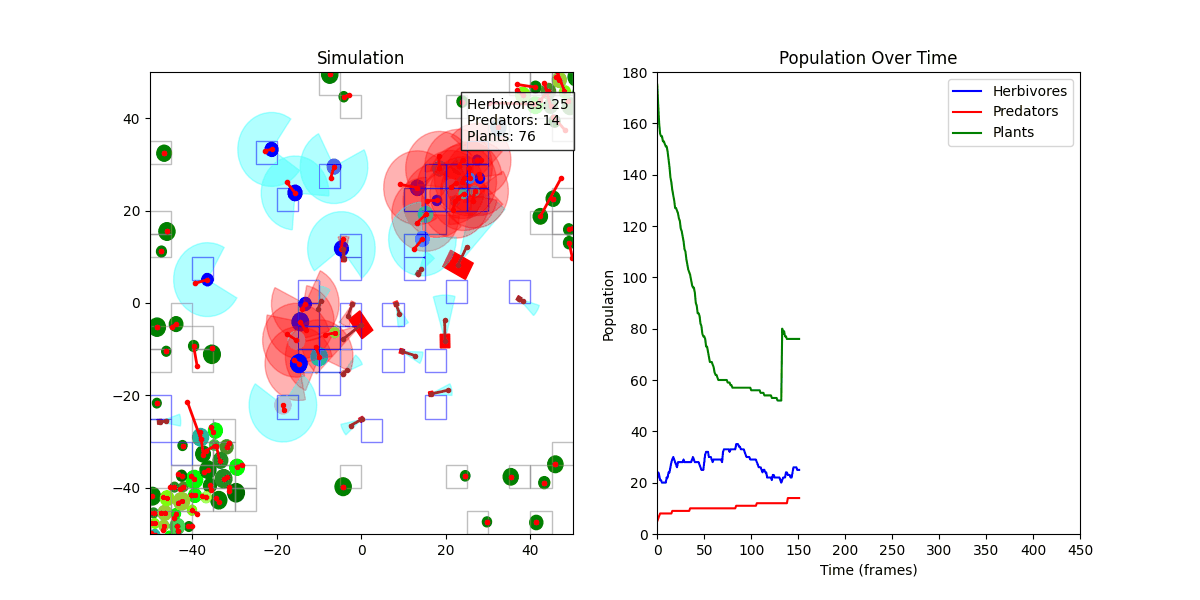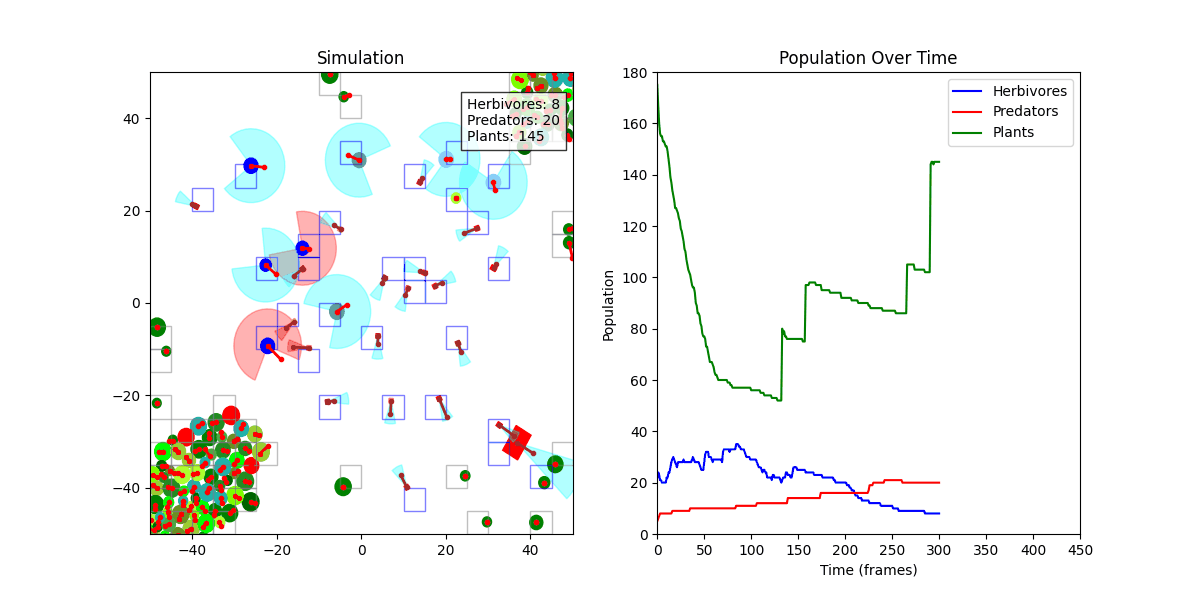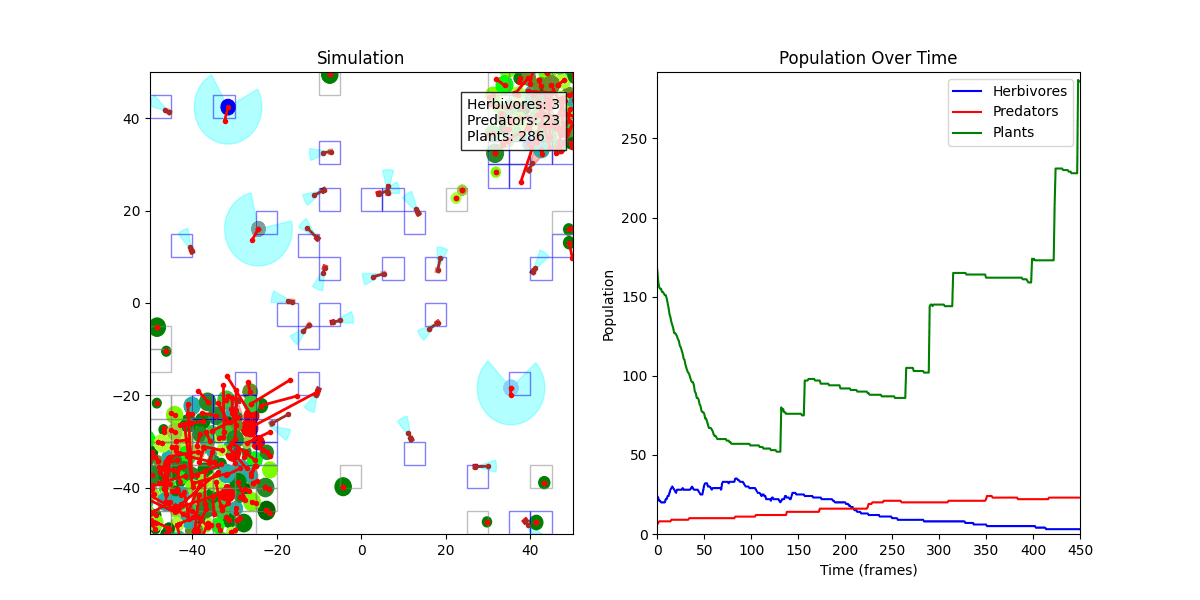
초기에는 쿼드트리(QuadTree) 기반으로 충돌 처리를 구현했으나, FOV 탐지 정확도 문제로 인해 Spatial Hash Grid 방식으로 전환했습니다.
1. 왜 쿼드트리를 포기했나?
쿼드트리는 공간을 사분면으로 분할해 탐색 효율이 높지만, 시야각(FOV) 처리가 어렵습니다. 객체가 여러 노드에 걸쳐 있는 경우, FOV 안에 있어도 누락되거나 FOV 밖인데도 탐지되는 오류가 발생했습니다. 이는 방향성과 각도를 기반으로 하는 FOV 계산과 쿼드트리의 정적인 분할 구조가 잘 맞지 않기 때문입니다.
2. Spatial Hash Grid의 장점
Spatial Hash Grid는 공간을 균등한 격자로 나누고, 객체 위치를 해시로 관리합니다.
- FOV 탐지에 유리: 주변 셀만 탐색하고, 이후 벡터 기반 각도 판단을 적용하면 정밀한 FOV 처리 가능
- 구현이 단순: 삽입/삭제 구조가 간단하고, 실시간 갱신도 효율적
- 성능 안정성: 객체 밀집 여부와 관계없이 일정한 탐색 성능 유지
FOV 시각화 및 실제 감지 범위 통일
처음에는 FOV(시야각)를 시각화만 하고, 실제 감지 범위는 고정된 반지름을 사용하고 있었습니다. 이로 인해 시각적으로 보이지만 감지는 안 되는 현상이 발생했습니다.
이를 해결하기 위해 다음을 적용했습니다:
get_adjusted_fov_radius()함수로 에너지 기반 가변 반경 도입is_in_fov()및detect_in_fov_for_type()모두 이 반경을 기반으로 동작draw_fov()에서도 같은 값 사용
추가적으로 FOV 반경이 너무 극단적으로 줄어드는 문제를 막기 위해 선형 감소 대신 루트 기반 보정을 적용했습니다:
def get_adjusted_fov_radius(self):
ratio = max(0.0, min(1.0, self.energy / self.ENERGY_UNIT))
return max(5, self.FOV_RADIUS * np.sqrt(ratio))
강화학습 구조와 적용 방식
환경 구성
SurvivalEnv: OpenAI Gym 스타일 환경- observation: 개체의 위치, 에너지, 속도 등 상태값
- action:
[dx, dy, detect_flag]형태의 연속값 - reward: 객체 내부의
compute_reward()함수에서 계산학습 방식 - 개체별로 PPO(PPO2) 모델을 각각 학습
PredatorEnvWrapper,HerbivoreEnvWrapper로 독립 학습detect_flag를 항상 활성화해 인지능력 사용보상 구성 예시 (Herbivore)- 식물 감지: +3
- 식물 접근: +5
- 포식자 감지: -5
- 포식자 근접: -30
- 포식자 멀어짐: 최대 +10
- 번식 성공: +5
- 생존 유지: +0.2Predator 보상
- 식물 감지 및 접근: +0.2 ~ +2
- 근처 식물 무시: -5
- 번식 성공: +5
환경 인터페이스 구성
e.g., HerbivoreEnvWrapper
import gym
import numpy as np
from collections import defaultdict
from SurvivalRL import SurvivalEnv, Config
class HerbivoreEnvWrapper(gym.Env):
def __init__(self):
self.env = SurvivalEnv()
self.observation_space = gym.spaces.Box(low=-np.inf, high=np.inf, shape=(4,), dtype=np.float32)
self.action_space = gym.spaces.Box(low=-1, high=1, shape=(3,), dtype=np.float32)
self.reward_breakdown = defaultdict(float)
def reset(self):
obs = self.env.reset()
self.reward_breakdown.clear()
return obs["herbivore"]
def step(self, action):
actions = {
"predator": np.array([0, 0, 0], dtype=np.float32), # predator는 고정
"herbivore": action
}
obs, reward, done, info = self.env.step(actions)
if "herbivore_breakdown" in info:
for k, v in info["herbivore_breakdown"].items():
self.reward_breakdown[k] += v
return obs["herbivore"], reward["herbivore"], done["herbivore"], {}
def render(self):
self.env.render(save_as="herbivore_train.mp4")
def close(self):
self.env.close()
학습 코드
from stable_baselines3 import PPO
from herbivore_env_wrapper import HerbivoreEnvWrapper
def train_agent():
env = HerbivoreEnvWrapper()
model = PPO("MlpPolicy", env, verbose=1)
model.learn(total_timesteps=100_000)
model.save("herbivore_ppo_model")
env.render()
env.close()
if __name__ == "__main__":
train_agent()
추론 코드
from stable_baselines3 import PPO
from SurvivalRL import SurvivalEnv
import numpy as np
model = PPO.load("herbivore_ppo_model")
env = SurvivalEnv()
obs = env.reset()
done = False
for _ in range(500):
if done:
break
herb_obs = obs["herbivore"]
action, _ = model.predict(herb_obs)
action = np.append(action[:2], 1) # detect always on
obs, reward, done, _ = env.step({
"herbivore": action,
"predator": np.array([0, 0, 0], dtype=np.float32)
})
env.render(save_as="herbivore_infer.gif")
env.close()
학습 환경에서 Reward 구조 연동
환경 클래스에서는 각 에이전트의 compute_reward() 호출을 통해 행동 평가:
obs, reward, done, info = {
"herbivore": self.herbivore.compute_reward(action["herbivore"], grid, self.game.objects), "predator": self.predator.compute_reward(action["predator"], grid, self.game.objects)
}
각 compute_reward()는 다음과 같은 구조로 동작:
detect_flag가 1이면 FOV 탐색 수행- 탐색 결과에 따라 타겟 설정
- 에너지 감소, 위치 이동
- 포식자 거리 계산
- 식물 접근 확인
- 번식 조건 만족 확인
- 보상 + breakdown 반환
최종 결과